ImageMagick中文使用手册:图像文件处理用法教程
ImageMagick中文使用手册:图像图片文件处理用法教程参数例子
要处理一个图像,你不仅需要操作符来进行处理,而且还需要从尽可能多的不同的文件格式中读取和写出图像的方式。
图像格式总结
ImageMagick最通常的用法不是用来修改图像,而是将图像从一种格式转换为另一种格式。实际上,IM’s创建的最初原因就是图像格式转换,这也就是为什么最主要的IM命令叫做”convert”。
为此,ImageMagick可以处理的图像阵列和文件格式令人眼花缭乱。添加到这个阵列的是内置测试文件、简单图像创建和专门用来编写脚本程序的图像格式及程序等的大量的特殊的输入和输出格式。完整列表见IM网页上的IM Image Formats Page。
对ImageMagick的新用户而言,这些使用起来并不轻松。我的建议是忽略大多数的文件格式,因为你极有可能永远也用不上它们。而更重要的是专注于你要做什么,并努力去做。如果你不知道怎么做,尝试从这些页和网页中来寻找相应的例子。IM示例中演示的图像格式,见 Reference Index, File Formats。
读取图像
默认情况下,IM将尝试根据文件本身的’magic’文件识别码来判断图像格式类型。如果这个失败,则你需要使用文件后缀或者添加前缀格式来指定图像文件格式。
有些格式将无法读取任何文件和忽略任何给定的文件名。这些都是一些常见的内置图像…
logo: granite: rose:
其中有些基于给定的参数生成文件名,也许一个额外的”-size”控制最终的图像大小……
-size 30x30 canvas:red -size 30x30 gradient:yellow-lime -size 30x30 pattern:fishscales import:
在一些情况下,你甚至可以使用多种格式:
-size 30x30 tile:pattern:gray95
这种情况有些过了,因为’pattern:’格式编码器有内置的’tile:’,但是它表达清楚了你想做的。
IM也可以通过指定图像的URL下载发表在万维网上的图像,这提供了’http:’的图像编码,也就是工作原理。
convert https://www.ict.griffith.edu.au/anthony/images/anthony_castle.gif \ -resize 100x100 castle_logo.png
![]()
如你所见,这个命令从WWW中读取图像,并且在将结果保存到磁盘之前调整大小。

当前缀的文件格式给定之后,作为文件名一部分的任何后缀与文件读取的方式没有任何关系。在读取一些如”text:” 和 “txt:” 的文件格式时,这至关重要。当然,如果图像生成器以特殊的方式来读取图像(如”tile:”),则后缀(或前缀)文件格式又将变得重要,就像最后一个例子所示。
文件名可以有一些特殊的文件元字符,如嵌入的’*’ 和 ‘?’等。IM将扩大这些字符来生成一个要读取的文件名的清单,避免了外部脚本来处理的需要,或者命令行长度限制的问题,例如:
montage '*.jpg' -geometry 50x50+2+2 image_index.gif
这将产生一个当前目录中所有JPEG文件的蒙太奇指数图像。但是需要引用参数来防止UNIX的脚本扩大的是文件名而不是ImageMagick。更完整的”montage”说明见下。
当然,linux shells也可以扩展传到其上的未引用的’*’ 和 ‘?’字符。但是在一些情况下,如果文件列表扩展到大量的文件名,会碰到命令行限制。
下面是使用Linux的shell来扩展文件名的其他例子…
convert image_[0-9].gif image_[1-9][0-9].gif animation.gif convert image_?.gif image_??.gif image_???.gif animation.gif convert image_(?|??|???|????).gif animation.gif
格式化递增文件名也见下面的Read Frames, Read Modifier 。
如果文件名仅仅是单个的字符串’-‘,IM将从标准输入中读取图像。
cat tree.gif | convert - -frame 5x5+2+2 read_stdin.gif

注意,一些图像文件格式允许你简单地将多个图像文件追加到一个长的多个图像流。这些格式包括PbmPlus/NetPBM 图像格式和IM’s自己的特殊文件格式MIFF:
for image in eye.gif news.gif storm.gif do convert $image miff:- done | convert - -frame 5x5+2+2 +append read_multiple_stdin.gif

在文件名开始的’@’特殊字符,意味着以给定的文件内容替换文件名,也就是说你可以读取包含文件列表的文件。
echo "eye.gif news.gif storm.gif" > filelist.txt convert @filelist.txt -frame 5x5+2+2 +append filelist.gif

你还可以和特殊文件名’-‘一起使用’@’来从标准输入中读取图像。
echo “eye.gif news.gif storm.gif” |\ convert @- -frame 5x5+2+2 +append filelist_stdin.gif


使用’@’句法从文件中读取文件名列表已添加到IM v6.5.2-1。

作为一个安全防范措施,这仅适用于与实际图像文件。它不能和如”rose:” 或 “label:string”等图像生成器一起运用。它也不能从文件中使用’include’命令行选项。
阅读编辑器或提取设置
图像在读入内存之后将被立即修改,但是是在图像被添加到当前图像序列之前。你可以指定一个”-extract”设置。例如,在这里我作玫瑰图像。
convert -extract 32x32+20+5 rose: +repage rose_extract.gif

或者你可以使用方括号'[…]’在文件名末端追加一个阅读编辑器,例如:
convert 'rose:[32x32+20+5]' +repage rose_read_modifier.gif

然而'[]’字符通常也是特殊的shell元字符,因此使用它来引用添加的编辑器,停止UNIX shells的解释,是一个好主意。
“-extract”设置和阅读编辑器的可进行同样的处理,但是后者将覆盖前者。
此外,当使用编辑器时,必须让IM处理任何特殊的文件扩展元字符,如’*’ 和 ‘?’,因为UNIX shell不会发现阅读编辑器要求的文件。这种情况下,究竟如何运行取决于shell。因此,在使用阅读编辑器时,将引用整个文件名。
阅读编辑器的真正目的是限制所需内存,图像仍然读入了内存,但是删除了不想要的图像或者使图像变小。例如,当读入一个大的JPEG图像的目录时:
这里是所有特殊阅读编辑器和”-extract”设置和其效果的列表。’#’代表一些数字。
‘[#]’ ‘[#-#]’ ‘[#,#,#]’ [#,#-#,#]’. 阅读帧
从读取的图像的多个图像文件格式中挑选特定的子帧时。给定的数字’#’指出了读取的特定帧数。多个索引可以以逗号命令或者以索引范围指定。
图像索引以0代表第一个图像,1地表第二个,依次往下。如果你指定了负的索引,则从图像序列末端数起。倒序的,-1代表最后一个图像,-2代表倒数第二个。
这和Image Sequence Operations使用的惯例是一样的。
例如:
convert document.pdf'[0]' first_page_of_pdf.gif convert animation.gif'[1-3]' second_to_fourth_frames.gif convert animation.gif'[-1,2]' last_then_the_third_frame.gif
你也可以基于一系列数字来读取图像,例如:
convert 'image_%03d.png[5-7]' ...
将读取图像”image_005.png”, “image_006.png”, 和 “image_007.png”。在这种方法中,你不能使用负索引。
‘[#x#]’ 阅读调整
从IM版本6.2.6-2起,添加了一个新的编辑器来帮助IM用户处理非常非常大的图像。
这个编辑器将调整刚读取的图像的大小,在图像添加到已经在内存中的图像之前。
这既可以缩小图像,也可以放大图像,如:
convert pattern:gray95'[60x60]' enlarged_dots.gif

注意:阅读编辑器目前并不使用任何调整大小的标志,如 ‘!’或’>’ 。
它还可以作为指定纯色画布大小的另一种方式,事实上正在发生的是它在调整默认的单一像素图像的大小。例如:
convert 'canvas:odgerBlue[50x50]' canvas_size.gif

当你尝试阅读大量的非常大的图像时,编辑器最为重要,因为每个图像将在下一个图像被读取之前调整大小,节省了大量的处理这些图像所需的内存。
例如,不使用
montage '*.tiff' -geometry 100x100+5+5 -frame 4 index.jpg
先读取所有的tiff文件,然后调整它们的大小,你可以使用:
montage '*.tiff[100x100]' -geometry 100x100+5+5 -frame 4 index.jpg
这将在进入到下个图像之前,读取每个图像,然后调整它们的大小。当达到内存限制时,造成更小的内存占用,防止磁盘调动(颠簸)。
对JPEG图像,我也推荐你使用特殊的”-define”设置代替,产生如下结果:
montage -define jpeg:size=200x200 '*.jpg[100x100]' -strip \ -geometry 100x100+5+5 -frame 4 index.png
在读取过程中,这个特殊的设置传递到JPEG库且用来限制JPEG图像的大小。但这并不准确,产生的图像的大小在那个尺寸或以保存的纵横比两倍的大小之间。更多细节见Reading JPEG Images。
组合的结果是更快的读取和JPEG图像更少的内存占用,尤其是当产生大量的缩略图时。见General Thumbnail Creation。
‘[#x#+#+#]’ 阅读裁剪
从IM v6.3.1起,如果你添加一个偏移量,上面将变成一大堆被读取的图像。
例如,从一个大的图像中截取一个600×400像素子区域。
convert 'image.png[600x400+1900+2900]' tileimage.png
在图像最终添加到当前图像序列之前,这将读取整个图像到内存,然后对图像进行裁剪。
如果你想处理非常大的图像,我建议你考虑”stream”命令,将你的图像传递到”convert”命令来进行进一步处理。见Massive Image Handling。
如果图像是”gzip”ed,IM会自动将其解压缩到一个临时文件,然后再尝试找出图像格式和解码图像文件格式。因此,你不仅可以以gzip压缩格式保存图像,而且之后的IM 处理直接使用。对于大型的基于文本的图像,这会节省巨大的磁盘空间。
PNG格式将”gzip”压缩作为其格式规格的一部分。在这种情况下,PNG “-quality”设置的两个数字中的第一个定义了压缩的程度。更多信息见PNG Image File Format示例。
上面的只是当读取图像到ImageMagic时可用的特殊的输入选项的一个小结。完整的总结在ImageMagick Website上的 The Anatomy of the Command Line 页可见。
如之前所示,图像输入可以被一些IM设置修改,例如”-size”来修改图像创建,”-define jpeg:size=??”来修改JPEG图像读取。其它选项也影响图像输入创新,包括”-page”, “-type”, “-dispose”, “-delay”。见 Setting/Changing Image Meta-Data。
当在脚本中传递一个用户提供的参数到IM中时要特别小心,确保参数是你所想要的。例如,你不会希望一个网页图像处理脚本返回一个系统口令文件图像。
输入文件名元字符的处理
不仅shell处理元字符(除非参数被引用),但IM也用自己的方式以文件名处理元字符。
例如:
convert *.jpg ....
被脚本在文件名传递到IM之前扩展,但是
convert '*.jpg' ....
将有shell 将”*.jpg”传递到ImageMagick,然后扩展为文件名的内部列表,这用来提供Windows Dos支持,也作为防止命令行限制”mogrify” 和 “montage”等通常用来处理长列表图像等命令的溢出。
因此,如果让IM在磁盘上命名为’*.jpg’的文件名,你需要使用下列中任何一种形式:
convert '\*.jpg' .... convert "\*.jpg" .... convert "\\*.jpg" .... convert [url=]\\\*.jpg[/url] ....
注意:第二行并不推荐,因为一些shells和APIs(C程序,可能是PHP)又可能删除单个的反斜杠,并且将’*.jpg’传递到IM使之再一次扩展。
在’?’ 和 ‘*’的顶端,IM也添加了处理’:’,’%’和'[…]’的元字符。
但是这对这些元字符的普通shell句法有着不同含义。
例如,DOS使用需要在传递到ImageMagick的文件名中避开’drive-letter’。例如:
convert C\:\path\to\image.jpg ....
另一个例子是上传一个带有时间密码的图像时,如:
convert "time_10\:30.jpg" ....
将从磁盘中读取文件名”time_10:30.jpg”。没有反斜杠,IM也许会认为图像应该以不存在的图像文件格式”time_10:”读取,以意想不到的方式失败。
另一种方法是使用一个问号:
convert "time_10?30.jpg" ...
但是这也有可能和如”time_10_30.jpg”的文件吻合。
压缩图像
IM也将读取被压缩的文件,并给予相应的后缀或图像格式规范。
也就是说以”image.gif.gz”保存的图像首先将被解压缩,然后从其GIF图像格式中解码。
Gzipped XPixmap (xpm) 和 NetPbm/PbmPlus (ppm)图像也会被Imagemagick和正常的格式委托库自动处理。因此,你可以直接在IM或者其它理解这些文件格式的程序中直接使用压缩形式。
见Saving Compressed Images。
保存图像
处理图像很重要,但是以正确的方式保存图像也同样重要。
“convert”, “montage” 和 “composite”的最后一个参数定义了最后写入的图像的文件名和图像格式,尽管你也可以使用”-write”(见下)在图像序列的中间保存图像。
指定想保存的图像的文件格式,你可以使用一个文件名后缀,比如我在所有的例子中使用的,或者以字符串”{format}:”为文件名加前缀。例如:
convert tree.gif GIF:tree_image
如果检查生成的图像,你会发现创建了一个GIF图像文件,尽管文件名本身并没有”.gif”文件名后缀。格式对大小写并不敏感,因此,你使用大小写均可。
当你想将图像保存到命令的标准输出时,图像格式规范就变得尤为重要。这种特殊的文件名没有后缀,所以你必须告诉ImageMagick使用什么格式,否则,图像将默认为原始图像的格式。
例如,我们使用了”-“写了一个IM像素枚举到屏幕来将结果输出到标准输出。
convert tree.gif -resize 1x3\! txt:-

它也可以通过一个shell ‘pipeline’来传递图像到另一个命令如”identify”,而不用保存在临时文件。
convert tree.gif -resize 200% miff:- | identify -
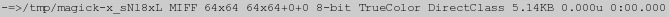
在这种情况下,你也可以看到特殊的”-“文件名也用来表示用”identify”命令标准输入中读取图像。更多信息见The Anatomy of the Command Line, Output Filenames上官方指南。
文件名百分号转义
保存的文件名可以包含一些特殊的百分号转义序列,具体有’%d’, ‘%x’, 和’%o’等,它使用C ‘printf()’格式将图像的’scene number’插入到文件名中。更多信息见Writing a Multi-Image Sequence 。
当然,这就意味着如果你想在文件名中插入百分号,你需要写两遍(‘%%’)。
在IM v6.4.8-4中,你也可以在最后的文件名中插入预先准备的特殊设置(必须以’filename:’开始)。例如:
convert rose: -set filename:mysize "%wx%h" 'rose_%[filename:mysize].png'

这将内置玫瑰图像保存为包含图像像素大小的文件。具体的,文件名”rose_70x46.gif”。这允许你使用任何的Image Properity Percent Escape 作为输出文件名的一部分。
注意只有’%[filename:label]’图像,Property 才可以在输出文件名中使用(和正常的’%d’转义),这个限制是出于安全考虑及正常的图像文件名可以包含’% 和 ‘[]’。
注意:不要在文件名设置中包含文件后缀。IM将忽略它,以原来的文件格式存储图像,而不是以文件名设置中包含的格式。也就是文件名将有你指定的后缀,但是图像格式可能不同!
‘filename:’设置不需要对每个图像都一样,你可以对每个使用的图像生成、计算或设置不同的设置。以下是另一个我修改一个图像,然后将其写入到新的文件名的例子。
convert eye.gif news.gif storm.gif -scale 200% \ -set filename:f '%t_magnify.%e' +adjoin '%[filename:f]'



这将放大每个图像,如”eye.gif”,然后将其保存到当前目录的”eye_magnify.gif”文件中。但是所有三个图像都读入内存,然后用一个命令修改。这不是处理大的和大量图像的推荐方法。
注意,这种情况下”+adjoin”对防止IM保存所有的图像到一个多个图像GIF动画中至关重要,而仅仅只使用第一个图像文件名。
也可以使用”%e”转义序列来确保保存文件名原来的后缀。通常在文件名设置中包含后缀并不是好主意,因为当其从转义序列中出现的时候,IM会忽略它。在这种情况下,图像格式没有变化,因此没有问题。
应用’%d/%f’ 或 ‘%d/%t.%e’来取得图像准确的原始文件名,你也可以使用IM在原始文件中发现的实际格式’%m’代替’%e’。请注意,内置图像的许多转义序列字符串都是空白。
使用’Filename Escape Sequence’的另一个例子在 Tile Cropping Images中,其中的技巧是为每个图像生成基于平铺位置计算的文件名。见Using Convert Instead of Morgify中的示例。
自动GZip后缀
如果给定了”.gz”后缀,IM将自动”gzip”图像。
例如,在这里,我以”gzip”ed未压缩的GIF文件保存内置”rose:”图像,我关闭了普通的GIF图像的LZW压缩,因为它会妨碍”gzip”压缩到最好状态。
convert rose: -compress none rose.gif.gz

浏览器如何处理一个gzipped图像取决于由web服务器返回的文件类型和你的浏览器如何处理压缩图像。因此,我不直接演示上面的图像。点击’art’图标,可看到你的浏览器如何处理来自web服务器的图像。
比较这种情况下和普通的LZW压缩下的GIF图像大小:
convert rose: rose.gif

“gzip”ed玫瑰是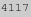 字节,而普通的LZW压缩的玫瑰的大小是
字节,而普通的LZW压缩的玫瑰的大小是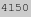 字节,正如你所见,GZIP压缩比GIF格式使用的LZW压缩要稍好一些,可能达到更好的效果。
字节,正如你所见,GZIP压缩比GIF格式使用的LZW压缩要稍好一些,可能达到更好的效果。
Gzipped更常用于在默认情况下,没有任何压缩的图像文件格式的长期存储。这包括IM文件格式”MIFF:”和更简单的NetPBM图像文件格式。
保存属性
其它设置特定于图像写入:
-depth -quality -compress -type -loop -set label -set comment
也见 Image Depth, Image Type, JPEG Quality, PNG Quality. GIF loop.
探讨作为各种文件格式的一部分的文件压缩。
不同的压缩适用于不同的图像格式。
尤其是JPEG到TIFF压缩变化的需要。
使用或”-compress None”和”-compress” NetPBM文本/二进制格式选择。
The GIF compression and the copyright patent.
GIF压缩和版权专利。
除了使用IM降低质量或将格式变为压缩选项已经使用过的其它格式,通常它只被IM内部用来以图像读取时相同的压缩来保存图像。
加密图像
IM也允许你使用选项”-encipher” 和 “-decipher”来以密码口令加密保存敏感文件。见Encrypting Images。
写入多个图像序列-毗连技术
保存这些图像的一个主要问题是ImageMagick一次将处理整个图像序列,而不是一个图像。因此,IM不会尝试写入当前图像序列中的所有图像到给定的文件名中。
如果文件格式允许多个图像,IM将默认保存当前图像序列中的所有图像到图像文件中。例如,如果你看GIF Animation Basics例子页,它会将多个图像帧保存到一个单一的图像文件格式来生成动画。
如果输出格式不允许将多个图像保存到一个文件中,IM将生成多个文件,例如,当保存为JPEG 和 PNG 等图像格式时。
你也可以通过使用”+adjoin”输出文件处理设置,在一个文件允许有多个图像的图像格式上强制使用,如GIF和PS。
convert eye.gif news.gif storm.gif +adjoin image.gif



如果你仔细研究上面生成的三个图像的文件名,会发现IM生成了命名”image-0.gif”到”image-2.gif”的图像。
ImageMagick 版本 6.2.0之前,上面的输出文件名是”image.gif.0″ 到 “image.gif.2″,因为文件名后缀的丢失导致了许多问题,因此在文件名后缀之前加入图像编号。
另一种方法是在输出文件名中添加’C language printf()’ construct “%d”,这个特殊的字符串将被替换为当前序列中每个图像的编号。
convert eye.gif news.gif storm.gif +adjoin image_%d.gif



在这里,我们使用下划线而不是IM默认的破折号,生成了图像”image_0.gif” 到 “image_2.gif”。
你不仅可以在十进制中使用’%d’,而且可以在十六进制(小写)中使用’%x’,在十六进制(大写)中使用’%X’,或者八进制中使用’%o’。
如果你实在想要一个被这些字母中的一个跟随的百分比字符,则需要双写百分号来转义,也就是说需要使用’%%’来确保生成百分号符号。
输出文件名中的’%d’实际上会自动允许ImageMagick的”+adjoin”设置。
然而虽然我并不实际需要在上面的”+adjoin”,但是提供也无妨,因此很清楚,你要生成单独的图像。
这适用于少量图像,但是如果有十个以上图像,你将得到一位和两位数字的图像的混合,如果你有一百个图像,则你可以得到三位数。当发生时,因为”image_15.gif”会照字母顺序地出现在”image_5.gif”之前,目录列表不会列出序列中保存的图像。
但是有修正这个的方法,例如使用如下的命令行shell表达式:
convert image_[0-9].gif image_[1-9][0-9].gif animation.gif convert image_?.gif image_??.gif image_???.gif animation.gif convert image_(?|??|???|????).gif animation.gif convert 'image_%d.gif[0-123]' animation.gif
最后一个方法是处理文件序列的适当的IM方式,尽管你需要知道你想使用的数字范围,’%d’规范每个数字来匹配文件名(见后)。
在任何情况下,这都是笨拙的且易于出错,如果文件丢失将产生错误,且取决于你所使用的电脑系统的类型,最好是完全避免这个问题。
如果你对’C’语言非常熟悉,则你极有可能知道如果使用如”%03d”的内容,也将得到3位数(以0开始)的图像序列帧数。这种情况下的图像名称可以是”images_000.gif”, “images_001.gif”等。
convert eye.gif news.gif storm.gif +adjoin image_%03d.gif



使用这种方法,图像不仅被编号,而且将以字母顺序排列,使图像文件处理容易许多。
因此,我建议当你打算写入多个图像时,添加一个’%03d’或者其它的合适的内容到输出文件名,就像单独的图像文件一样。
如果你希望图像序列以’1’而不是’0’开始,且不想重命名所有的处理后的图像文件,最简单的方法是在即将写入的图像序列的最前端预先设置一个’junk’图像。
convert null: eye.gif news.gif storm.gif +adjoin image_%01d_of_3.gif rm image_0_of_3.gif



当然,你可以在处理之后使用”+insert”来达到这个目的。这并不是一个漂亮的解决方案,但是能够运行,且简单,并且和IM旧的主要版本都能后向兼容。
在IM 版本 6.2中,你可以使用”-scene”来设置当前图像序列的起始号。
convert eye.gif news.gif storm.gif +adjoin -scene 101 image_%03d.gif



将生成”image_101.gif”到 “image_103.gif”的图像文件。
多次写入一个图像
尽管是再写入图像的主题下,也可能使用特殊的”-write”图像操作符来从图像序列的中间写入图像。
当你想在图像处理过程中的不同点输出一个图像多次,这是非常有用的。例如,见Complex Image Processing with Debugging。
下面例子中,我有一个Photo of some Parrots,由Kodak Lossless True Color Image Suite (图像23)提供,我想使用一个命令将其保存为一系列不同的尺寸。
convert parrots_orig.png \ \( +clone -resize x128 -write parrots_lrg.jpg +delete \) \ \( +clone -resize x96 -write parrots_big.jpg +delete \) \ \( +clone -resize x64 -write parrots_med.jpg +delete \) \ -resize x32 parrots_sml.jpg




如你所见,我们可以使用 Image Sequence Operators来处理图像的一个’clone’,写出结果,删除,然后返回到源图像,根据你的需要重复这个过程多次。
在这种特殊情况下,这意味着我不仅反复调整同一图像的大小,因此而积累调整错误。而且意味着我可以容易地首先生成小一点的图像,之后大一点的图像,或以不同的方式修改每个图像文件生成的图像。
这也就是说顺序和每个图像的修改是不相关的!
注意:”+clone”实际上不重复图像数据!IM使用了reference-counted的克隆处理,只是在更新的时候复制图像像素。因此,只需要足够的内存来存储上述过程中实际使用过的源图像和生成的新图像。它也使”+clone”的速度更快,更节省内存。
下面是进行相同处理的另一个技巧,但是使用”MPR:”代替”-clone”,将原始图像存储到一个命名的图像寄存器中。
convert scroll.gif -background lightsteelblue -flatten -alpha off \ -write mpr:scroll -resize x128 -write scroll_lrg.jpg +delete \ mpr:scroll -resize x96 -write scroll_big.jpg +delete \ mpr:scroll -resize x64 -write scroll_med.jpg +delete \ mpr:scroll -resize x32 scroll_sml.jpg




这里,我们保存原图像的一个副本到”mpr:scroll”图像寄存器中,然后修改写入后还在内存中的图像,一个MPR寄存器实际上可以保存图像的整个序列。
一旦这个操作的结果被写入了且从内存中删除了,原图像或图像序列将恢复,这个处理过程可按需要重复多次。
当然,就像以前没有必要在最后的图像上使用”-write”,因为我们只输出正常图像,如果你确实使用了”-write”,你可以使用另一个特殊的文件格式”NULL:”来废弃最后一个图像。
关于”-write”的警告:因为一些一些文件格式要求图像以特殊的格式来写入,”-write”操作符可以修改图像。PNG图像可以转换为RGB彩色空间,GIF图像可能被减少颜色等等,但是其它的格式将保持源图像。
通过写一个Clone或者使用MPR来生成文件的副本,可以使你免受这些变化。另一种方式,你可以使用生成或删除写入图像的内部副本的”+write”。但是,使用这些技巧会导致写入修改和复制图像占用的内存加倍。
特殊文件格式(针对IM)
如上所见,ImageMagick懂得大量的知名的图像文件格式,它也包括相当数量的特殊图像生成器,在这些之上,有许多针对IM的特别特殊的文件格式,这些格式允许图像的一些非常特殊的处理。
所有这些特殊文件格式都是读取和写入的格式。
miff:
是ImageMagick文件格式,整个图像序列和图像的所有相关属性都存储在这个文件格式中,当然,只有 ImageMagick命令读取这种格式,所以它不适合长期或不同图像处理程序包之间的转移。
“miff:”文件格式的初衷是在大的图像处理脚本中或者’pipelining’一个图像从一个IM命令到另一个命令时,作为中间存储格式,见最后一个例子。
我建议在写入”miff:”时包含一个”+depth”选项,这将根据IM内存质量来调整输入深度,以便使用所存储的中间图像的最好质量。当然你可以使用”-depth 8″ ‘clip’存储图像的深度,以便缩小磁盘上的图像尺寸,但是,这也将强制Quantum Rounding起作用(除非HDRI floating-point save 开启了)。
对该格式的句法分析感兴趣的人来说,它是一个半文本格式,由以下组成:一个图像属性的ascii 头,含有单个的换页符的一行,紧随其后的是作为二进制的原始图像数据。这个头是从各种图像处理脚本中提取基本图像信息的有效方式。
例如,在这里我使用了一个GNU-sed命令来列表”miff:”一直到换页分隔符,显示内置的”rose:”图像的所有属性。
convert rose: miff:- | sed -n '/^\f$/q; p'
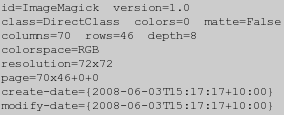
当显示所有IM所知道的当前设置的标记和元数据时这非常有用,但是也有统计,因为这些都是由 “identify”命令、”-identify”操作符,或者特殊的”info:”格式生成的,如果有”-verbose”选项。(见下)
“miff:”格式是一个’streaming’图像文件格式,也就是说多个图像通过将图像一个接一个地追加到一起简单处理。
这意味着你可以简单地将图像写入相同的目的地,比如管道,来生成多个图像的一个’stream’。即使单个图像由不同的命令生成。
例如,你可以设置一个图像处理命令的循环,每个命令只输出一个’streaming’ MIFF 图像。在循环之后,你可以将图像’stream’传递到一个单个的命令来生成蒙太奇、拼贴画、动画或者其它内容。
例如,下面的将生成一个以字母“B”开始的颜色列表,然后使用一个”convert”命令的循环来生成色块和标签,一次一种颜色。然后传递到”montage”中来生成简单的颜色表。
convert -list color | egrep '^b' | \ while read color junk; do \ convert -label $color -size 70x20 xc:color +depth miff:-; \ done |\ montage - -frame 5 -tile 6x -geometry +2+2 \ -background none color_table.png

上面具体的例子被编入在图像处理过程中,可用来搜索、查找和显示颜色的脚本”show_colors”。
上面的是’Stream of Pipelined Images的一个例子,’Stream of Pipelined Images在生成如Layered Image Example中的图像序列或者如 Random Ripples中的动画时非常有用。
这个技巧也可以和如”-write miff:-“等操作一起使用,以便以一个单一的命令从多个图像中输出miff格式图像,每个图像将在最后的输出流中自动追加到一起,这对调试复杂图像处理命令尤其有用。
最后,这个格式(在没有压缩时)可以处理IM所知的任何类型的图像,它几乎是用于临时图像和传递图像命令的最理想的格式,尽管只有可以读取。
确实是一个非常有用的图像文件格式。
见下面的”MPR”图像内存寄存器和”MPC”内存磁盘映射格式。
info:
“info:”文件格式(在IM v6.2.4中添加)不会输出实际图像!这个格式只是输出和ImageMagick “identify”将输出的相同信息。
就像”identify”这种输出格式,被”-format” 和 “-verbose”选项控制,允许你只输出你感兴趣的特定信息,依照由 Image Property Escapes页定义的。
例如,不像我们上面所做的传递MIFF图像到”identify”(见Saving Images),我们可以使用下面的来返回处理后图像格式的单线识别。
convert granite: info:-
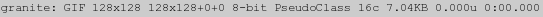
当然,你可以使用一个 “-format”设置来以特定和更一成不变的方式输出想要的信息。
对”info:”最重要的是,可以在生成图像的同时提取图像的额外信息,这通过使用”-write”操作符来保存这种特殊的图像格式到一个文件(或者命令正常标准输出)中来实现。
convert rose: -shave 12x0 -repage 64x64+9+9 \ -frmat '%wx%h %g' -write info:info_paged.txt paged.gif

在输出图像识别信息到标准输出中时,使用”-identify”操作符和”-write info:” 是一样的,”-identify”操作符甚至使调试IM命令时监视到底如何进行的变得更为容易。例如:
convert logo: -identify \ -trim -identify \ +repage -identify \ -resize 80x80\! -identify \ logo_thumbnail.gif
![]()

这里,你可以看到”-trim”时如何减小图像的尺寸但是图像的哪部分被切了的’crop’信息,然后”+repage”删除额外的’canvas’ 或 ‘page’信息,等等。
同样像”identify”命令,如果”-verbose”设置启用了,”info:” 和 “-identify”都将变得更详细。在这里我将长输出限制至开始的几行,这样你可以得到关于它的一些概念。
convert rose: -verbose info: | head
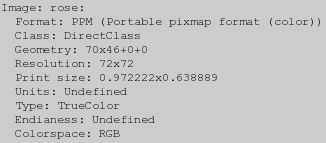
“-verbose”设置也将图像的额外信息被读入或读出,被输出到标准错误句柄(”info:”格式除外)。它也导致一些如”-colors”的操作符输出其它信息。因此你可能想在将它和”-identify”或”info:”格式使用时候关闭它。
例如 “-verbose -write info:image_info.txt +verbose” 或 “-verbose -identify +verbose” 。
脚本读取来源于”identify”的任何形式的输出时,需要以案例不敏感的方式。这保证了ImageMagick的不同版本之间更好的后向兼容性。
注意:”info:” (和 “-identify”)只是一种输出格式,生成和”identify”命令相同的输出,不能使用它来读取或创建图像。
你也可以使用”-print”来输出信息,但是一旦应用就是针对整个图像序列,这意味着你可以使用这个操作符来演算包含多个图像的更为复杂的’%[fx:…]’表达式,但是需要记住,和上面的其它方法不同,它将应用到所有图像。
null:
作为一种输出格式,它仅仅’junk’处理后的图像,因此如果在”convert”, “montage”, 或 “composite”命令中作为最后参数使用,最后的结果将不会被存储。
为什么?因为你可能会对在图像处理中生成的特定图像而不是整个结果感兴趣,特别是在调试的时候。
例如,我们从一个图像序列中提取和保存一个图像,然后使用”null:”.来废弃其它图像。
convert eye.gif news.gif storm.gif tree.gif rose: logo: \ \( -clone 2 -write write_storm.gif \) null:

这比尝试一次删除一个的来删除所有图像要简单的多。
但是作为一种图像输出格式,”null:”将在当前图像序列中生成一个带有特殊的’null source’标记的单一透明像素的占位符图像。
这个特殊的图像对 Leave Gaps in a Montage特别重要,且是多图像 Layer Composition的分隔符。它和另外一种可以由”-crop”等操作生产的’missed image’密切相关。这种图像格式一个操作生成的是空的或者不明显结果时产生,两种图像都是单一透明像素,因此”null:”图像也可以被作为’missed image’对待。
目前,还没有从当前图像序列中删除任何”null:” 或 ‘missed image’的方法,但是这种方法已经提出了,如果需要使用写邮件给我。
txt:
这是一种简单的ASCII文本文件,以每行一种的方式列出图像中的每种像素。它并不是图像格式转换的常用文本,示例见Multi-line Text Files Examples。
例如,这里是一个缩小到2×2像素的”netscape:”图像,然后用”txt:”图像格式列出。
convert netscape: -scale 2x2\! txt_netscape.txt
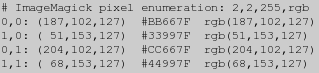
第一行被图像的基本信息充满,信息由以下组成:
File Magic: File Magic:图像文件头被定义成一个特殊的IM文本图像格式(如“ImageMagick pixel enumeration”文件),它可以被计算程序所识别,因为“magic”文件或者代码字符串将这个文件标识为指定的文件格式。
Image Size: 接下来的两个数字定义了这个文件包含的图像的尺寸,将这些数字相乘也将得到在第一行之后还需要多少行来完整地定义这个图像。
MaxValue: 第一行的最后一个数字定义了图像数据可能的最大值,在上面的示例中,这个数字是使用8位深度的结果的’255’。
以这个深度输出内置”rose:”的原因是内部定义使用8位值,也因此IM保存这个深度。更多信息见depth setting 中的部分。
但是你可以通过改变图像的”-depth”,覆盖深度设置(直到达到IM限制)或者 Compile-time Quality设置。如下,输出颜色值为16位(或者从0到65535的值)。
convert netscape: -scale 2x2\! -depth 16 txt_netscape_16.txt
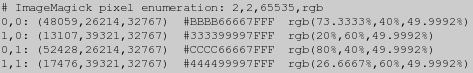
在这时,你不能设置一个特定的’Maximum Value’来在输出文件格式中使用,只能根据当前的”-depth”设置来定义一个不同的值,使最大值等于2^depth-1。
Colorspace: 第一行中的最后一项定义了数据所遵照的色彩空间。如果图像包含任何透明度,将在色彩空间名的最后添加一个字母’a’(代表阿尔法),且在圆括号内添加了一额外的数字列。灰度图将使用’rgb’格式,尽管这三个数字都将是同样的值。
例如,下面是同样的图像使用添加了阿尔法通道的’LAB’的colorspace。
convert netscape: -scale 2x2\! -colorspace LAB -matte txt_cspace_lab.txt

在第一行之后是像素数据行,列举图像中的每个像素。
Coordinates: 开始的两个数字直到冒号’:’是像素位置,从0开始。
Color Values: 在这之后,像素的颜色值(从0到文件头中给定的最大值)在括号内给定,有3到5个数字,取决于图像当前的色彩空间。空间是可选择的,因此在解析括号内的数字时需谨慎。
Color Comments: 括号内跟在数字之后的内容都被当做是注释,IM将使用可以解析为颜色参数的格式来填充像素颜色的额外信息(更多颜色规格的信息见”-fill”手工录入)。
但是颜色注释是多变的,且可能根据给定的像素数据输出RGB()或颜色名字。提供的是什么颜色注释主要取决于你所使用的IM版本,特别在早期的IM v6和之前的版本。不保证此注释区域将来不会再更改,所以最好不要依赖它。
以下是正确读取一个shell脚本的像素枚举。TXT图像的格式是由转换命令定义的,然后’tail’用来废弃图像文件头,’tr’字符使用单个空格替换每个非数量字符,因此之后的’while’可以容易地读取它,废弃所有可能留下的任何注释数字。
convert rose: -resize 3x2\! -depth 8 -colorspace RGB +matte txt:- | tail -n +2 | tr -cs '0-9\n' ' ' | while read x y r g b junk; do echo "$x,$y = rgb($r,$g,$b)" done
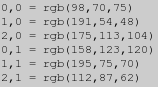
读取TXT图像也是有效的,你不需要定义图像中的所有像素,甚至不需要以正确的顺序排列像素。ImageMagick将一次读取每个像素,然后将其拖到一个空白的图像画布中,只有每行中圆括号内的数字用于这个,而不是颜色名称。
开始的空白画布,被清除了且设置为当前背景色,因此任何不是由”txt:”图像提供的任何像素,都将以这种颜色留下。
“txt:”和”-unique-colors”操作符使用时尤其有用,将以新的以一种像素代表每个单独颜色的图像替换当前图像序列中的每个图像。当这输出为”txt:”格式文件,你将得到图像所包含颜色的简单总结(尽管不是计数或直方图)。
比如以下是被这单个图像使用的颜色,因为GIF只能使用8位数字,颜色也以同样的深度输出。
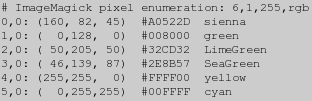
convert tree.gif -unique-colors txt:-

还有另一种方法来使用IM “txt:”格式:使用各种 NetPBM image file formats。默认情况下,IM将以二进制输出这种格式,但是你可以关闭”-compress”来输出NetPBM格式的ASCII文本版本,例如:
convert tree.gif -unique-colors -compress None -depth 8 tree_netpbm.ppm
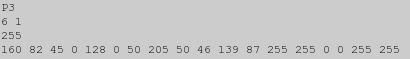
你可能注意到了上面的数字和IM枚举像素(“txt:”)格式的数字相吻合,生成一个NetPBM格式图像供IM读取的示例见Resized Gradient。
如果只想要特定像素的颜色,你可以裁减图像至一个像素且以”txt:”图像输出。
convert rose: -crop 1x1+12+26 txt:

或者你可以使用特殊的 FX Escape Format以IM直接使用的形式来输出颜色。
convert rose: -format '%[pixel:u.p{12,26}]' info:
![]()
也见Extracting Image Colors。
直方图:
这实际上是”miff:”图像格式,但是有一个非常大的包含图像中所有的颜色的完整计数的图像注释,这就是”miff:”文本头’Comment={…}’属性。
例如,我们再次列出树图中像素的颜色,但这次包含每种颜色的像素统计,从”histogram:”图像中,使用一个辅助的”info:”格式标识提取了文本直方图注释。
convert tree.gif -define histogram:unique-colors=true \
-format %c histogram:info:-
“info:”输出格式已被添加到IM v6.2.4中,在这之前IM使用:
convert tree.gif histogram:- | identify -format %c -
你会注意到,这个格式和之前的TXT,或IM 像素枚举图像格式一样,在颜色值中包含注释,唯一不同的是X,Y的位置被像素计算取代。
这个注释可能需要较长的时间来生成,如果不需要的话,在IM v6.6.1-5中,你可以添加特殊的设置”-define histogram:unique-colors=false”来关闭注释生成
图像本身是一个直方图,256×200像素大小,x轴是颜色值(0-255),y轴是像素统计(标准化的像素数)。每个通道的直方图以所出现的颜色显示,然后添加到一起。因此,红色和蓝色重叠生成品红色。换句话说颜色通道都有自己独立的的直方图。
如果你想图像转换为其它格式,只需保存为其它格式。”histogram:”是一种特殊的图像处理格式,它会转换图像,然后输出文件名后缀或更进一步的”format:”代码指定的格式。
convert rose: \ -define histogram:unique-colors=false \ histogram:histogram.gif
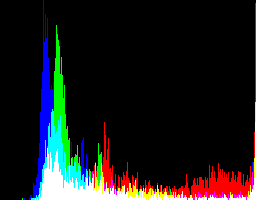
一个非常暗的图像将偏向左边,而一个两的图像则将偏向右边,中间色调,则将显示在中间。
为看的更清楚,我在这里分离每个颜色通道的直方图,我也剥离了直方图文本注释,调整了图像的大小来供显示。
convert histogram.gif -strip -resize 50% -separate histogram-%d.gif
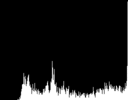

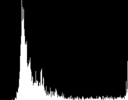
Red Green Blue
对于上面的”rose:”图像,你会看到红色伸展的更多显示了它在图像中的重要性。另一方面绿色和蓝色左边的尖峰显示了它们对图像的影响微乎其微。
如果你对图像的亮度而不是颜色更感兴趣,在生成”histogram:”图之前将图像转换为灰度图像。
convert rose: -colorspace Gray \ -define histogram:unique-colors=false \ histogram:histogram_gray.gif
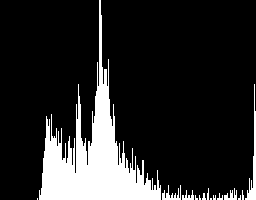
正如你所见,灰度图像的直方图有一些不同,因为占主导地位的变成了更偏向中间的灰色,在直方图的中间产生了一个尖峰,图像的白色小区域在直方图右边产生了一个明显的尖峰。
极左边的完全空的区域也显示了图像中根本没有暗块。
另一方面,一个更好的’global’直方图可以由简单的分开源图像和追加图像的所有颜色通道生成。生成的直方图显示了所有的颜色值,但忽略了该颜色来自哪个通道。
convert rose: -separate -append \ -define histogram:unique-colors=false \ histogram:histogram_values.gif
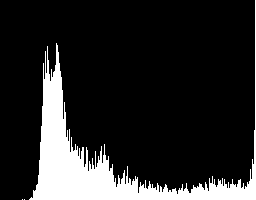
但是不幸的是,”histogram:”是一种输出格式,如果你想进一步处理图像,你需要’pipe’图像到另一个命令,图像存到磁盘,或者使用特殊的”mpr:”存储或读取。示例见下面的”mpr:”。
如果一些生成直方图(和其它图表)的方法变得和操作符一样可得,而不是特殊的输出格式,将会更好。
mpr:{label}
(内存程序寄存器)将整个图像序列保存至一个命名的内存寄存器,稍后可以从中读取图像数据。因此,如果你想保存一个图像供以后使用,在复杂的图像操作中,你可以如此进行。
在处理的末端写入”mpr:”,在程序寄存器被返回到系统之后将立即失效。因此,你会想使用一个Write操作来在图像处理步骤中间保存图像。
“mpr:”的’label’可以是任何你喜欢的内容,它只是一个图像存储在内存的何处的标签。对在进行脚本撰写且不像处理名称的人,它甚至可以是一个简单的数字,尽管名称将使你的脚本更容易阅读。在你存储了一个图像之后,你可以从相同的’labelled’内存位置再次读取图像,进行多少次都可以。例如:
convert tree.gif -write mpr:tree +delete \ mpr:tree mpr:tree mpr:tree +append mpr.gif

注意上面图像处理过程中”+delete” 的使用,在将图像保存到”mpr:” 寄存器之后,从当前图像序列中删除所有图像是非常正常的,然后清理运行的内存来进行下一步的图像处理。因此,上面的两行可以被认为是两个完全独立的”convert” 命令,但是使用了一个命名的内存存储器而不是磁盘空间来存储中间图像。
在很多方面,使用”mpr:”很像使用 Clone ,但是完全从当前图像序列中提出图像来处理。
这种方法最好的前景是它也允许你使用只在图像输入中使用的设置和操作符,例如:和输入图像”tile:”操作符一起使用来将图像平铺在一个更大的区域。
convert tree.gif -flip -write mpr:tree +delete \ -size 64x64 tile:mpr:tree mpr_tile.gif

你也可以使用”mpr:”来抓取一些特殊的输出图像格式过滤器的输出来进行进一步处理。比如,我们在真正写入图像之前,抓取”histogram:”的输出图像,然后进一步处理,生成一个较小的直方图表。
convert rose: -define histogram:unique-colors=false \ -write histogram:mpr:hgram +delete \ mpr:hgram -strip -resize 50% istogram_resized.gif
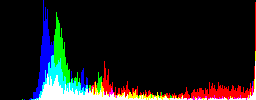
“mpr:”在内存存储实际上是唯一的可以再次使用已经在内存中的图像的方式,通过像”histogram:”的输出文件格式或像”tile:”的输入文件格式等特殊的I/O过滤器。
这同样符合于采取实际输入图像的特殊操作符,比如”-tile” 或”Color Mapping”图像使用另一个图像作为来源。见Multi-image Color Maps。
它也是唯一的使用-draw ‘image’ 方法应用已在内存中生成的图像来覆盖图像的方式,尽管还有很多更好的方法来进行这样的处理。
注意,”mpr:”实际上保存整个图像序列而不仅仅是一个图像,这有点像当前图像序列的快照,以便你之后做进一步处理。比如,这让你得到整个动画序列的副本,通过复制或克隆,而不需要究竟包含了多少图像。示例见Layers Composition。
Image Cloning 操作符通常不能处理未知的可变数目的图像,实际上在 Clone 操作符被添加之前,”mpr:”是唯一的复制内存中图像的方法,不需要使用中间磁盘文件。
mpc:
是一个特殊的IM特定磁盘存储格式,原本用来存储大的图像。它是程序内存的内存映射的磁盘文件,以两个二进制文件保存到磁盘,”.mpc”处理图像的元数据,”.cache则处理图像像素缓存。
“MPC:”格式创建两个文件来保存一个图像
这样的文件在IM被重新编译或更新之后不能运行,并仅适用于特定的机器编译的IM,因此,它仅适用于临时’quick read’文件,比如,脚本图像处理使用的临时图像,且不是长期储存。
convert very_big_image.tif very_big_image.mpc
将在磁盘上生成两个文件。一个小的”very_big_image.mpc”文件和一个称为”very_big_image.cache”的特殊信息转储文件。第二个文件大小可能比其他任何图像文件格式都要大,因为它是原始的未压缩的信息转储。
这个文件不需要读取或解码,但是可以直接’paged’到电脑内存中,直接使用,不需要提前做任何处理,只需要大量的磁盘空间和磁盘IO,换句话说,它只需磁盘访问时读取,而没有任何文件格式处理,也就是说没有数据的解码。
因为图像是’memory-ready’,对所有尺寸的临时图像都是非常有用的,且可立即用于你所使用的下一个IM命令。但是需要记住:生成两个文件,且比普通图像文件尺寸要大,因此要当心磁盘使用和脚本清除。
我自己的IM脚本充分利用了这个,如”de-pixelate”和”divide_vert”脚本,它们利用大量的临时图像文件来进行图像处理操作。
这对需要一遍又一遍地读取同样图像的脚本或Mogrify Alpha Compositing 十分有用,因为IM不需要解码图像或者用大量的内存来存储图像。
这对从一个大的图像中提取或 Crop 一个小的区域来进行实际处理也相当有用。但是因为大多数的图像操作符实际上在处理过程中克隆副本,一个新的内存中的复本,仍然可以生成。因此还是需要一些谨慎。对MPC大图像处理而言,利用 Crop 或 Resize来得到更小图像尺寸是最安全的操作。
更多信息见Really Massive Image Handling 。
fd:{file_descriptor}
这个特殊的文件名,允许你指定图像被读取或写入的特定’file descriptor’。
名称’fd:0’是’standard input’,’fd:1’是程序的’standard output’。这些等同于使用’-‘作为文件名。
但是你可以指定任何’file descriptor’来读取或写入图像,包括’fd:2’ 为 ‘standard error’,或者任何其他以前打开的文件处理可能安排的父程序。
这个最常见的用途是在可能有多个图像的文件流的高级shell脚本中,或者用于多个文件流同时打开的网络后台程序。
inline:{base64_file|data:base64_data}
内置图像让你读取以特殊的base64编码定义的图像。
例如,读取一个base64编码图像使用:
inline:base64_image.txt
这个编码可以来源于文件,但是更通常是作为读取参数而不是来源于外部图像文件的文件名直接给出。更典型的是作为命令行上的’blobs’的替代,或者在API图像处理中使用。
或者在命令行中直接放置图像数据:
inline:data:mime-type;base64,/9j/4AAQSk…knrn//2Q==
例如让base64编码一个非常小的图像(有许多程序允许进行这个转换):
openssl enc -base64 -in noseguy.gif

注意:base64数据可以包含任何数量的白色空间,比如返回和换行符,它将被简单地忽略。它也只使用普通的ASCII字符,这也就是为什么它用来在邮件和网页中编码二进制数据。它也允许在程序和脚本中存储二进制数据。
例如,我可以在shell脚本中有以下命令,因此脚本本身有内置的图像,而不需要一个单独的外部图像源。
convert 'inline:data:image/gif;base64, R0lGODlhIAAgAPIEAAAAAB6Q/76+vvXes////wAAAAAAAAAAACH5BAEAAAUALAAA AAAgACAAAAOBWLrc/jDKCYG1NBcwegeaxHkeGD4j+Z1OWl4Yu6mAYAu1ebpwL/OE YCDA0YWAQuJqRwsSeEyaRTUwTlxUqjUymmZpmeI3u62Mv+XWmUzBrpeit7YtB1/r pTAefv942UcXVX9+MjNVfheGCl18i4ddjwwpPjEslFKDUWeRGj2fnw0JADs= ' b64_noseguy.gif

注意,这个图像可以在你的脚本中使用,你不需要单独的外部图像文件,使简单的脚本安装更为复杂。
为什么”inline:”有这么复杂的形式?
主要是因为这是用于HTML网页的内联图像的格式,例如,下列右边的图像使用HTML标记形式直接在网页上内嵌,而不是作为单独的外部文件。
<IMG SRC="data:image/gif;base64, R0lGODlhIAAgAPIEAAAAAB6Q/76+vvXes////wAAAAAAAAAAACH5BAEAAAUALAAA AAAgACAAAAOBWLrc/jDKCYG1NBcwegeaxHkeGD4j+Z1OWl4Yu6mAYAu1ebpwL/OE YCDA0YWAQuJqRwsSeEyaRTUwTlxUqjUymmZpmeI3u62Mv+XWmUzBrpeit7YtB1/r pTAefv942UcXVX9+MjNVfheGCl18i4ddjwwpPjEslFKDUWeRGj2fnw0JADs=" ALT="Nose Guy" WIDTH=32 HEIGHT=32 VSPACE=5 HSPACE=5 BORDER=0 >
这并不适用于所有的网页浏览器,例如,在IE7或者之前的版本都不能运行,但是在IE8中可以运行。基本上最现代的网页浏览器可以理解。
同类型的内联图像格式也用于邮件头中的’face’图像,也有可能用于许多其它文件类型。
旁白:由于ImageMagick中的’magic’部分,大多数图像文件不需要包含互联网媒体类型(长字符串中的’image/gif’部分)。事实上,它完全被IM忽略。但是需要逗号’,’来标记内联图像数据字符串部分的结束。
convert 'inline:data:,R0lGODlhEAAOALMAAOazToeHh0tLS/7LZv/0jvb29t/f3//U b//ge8WSLf/rhf/3kdbW1mxsbP//mf///yH5BAAAAAAALAAAAAAQAA4AAARe8L1Ek yky67QZ1hLnjM5UUde0ECwLJoExKcppV0aCcGCmTIHEIUEqjgaORCMxIC6e0CcguW w6aFjsVMkkIr7g77ZKPJjPZqIyd7sJAgVGoEGv2xsBxqNgYPj/gAwXEQA7 ' b64_folder.gif

警告:命令行选项输入被限制为5000字符,许多shells(特别是PC-DOS输入)有总命令行长度限制,因此这对非常大的base64图象并不适用。
clipboard:
从Windows剪贴板(只有Windows)中读取图像或写入图像到Windows剪贴板中。
ephemeral:{image_file}
读取然后删除图像文件。
这是一个特殊的图像读取文件格式,使IM在图像被读取到内存之后删除给定的图像文件。
这是非常危险的,需慎用。
它用于Delegate Spawning中的例子,背景委托将会读取输入的图像,当获得数据之后则将删除图像。这反过来将通知前景’parent’程序,’child’能独立处理,因为它已经读取了提供的图像。然后主程序可以清理和继续其图像处理,或者像例子中的简单退出。
“show:”图像输出委托
将其和”display”命令一起使用,在主命令继续或退出之前自动显示图像背景。(见下)
show:, win: and x: — 在屏幕上直接显示图像
这些都是可以直接在屏幕上显示图像处理结果的特殊输出格式,而不是将图像保存到文件,仅仅显示结果。
对快速试验IM命令将产生什么结果十分有用,也强烈建议使用。但是它们只是”display” 和 “animate”命令的简单版本。
例如,得到目录中图像的快速摘要:
montage *.jpg show:
见两幅图中的不同区域:
compare image1.png image2.png show:
所有列在此的格式,实际上访问”display”程序来执行任务,但是它们每个以不同的方式处理。
例如’show:’ 将使用Spawning Delegate来运行一个单独的”display” 程序,这意味着一旦图像显示出来,原来的命令将继续处理。在上面是运行的最后一个操作,所有原始命令将退出,在将背景中的源图像显示的同时,返回命令行提示。
另一方面,使用’x:’ 或 ‘win:’将等你退出显示窗口,然后让原始命令继续(或退出)。
不幸的是,这些方法中没有可以很好地显示动画的,因此,最好将动画(MIFF格式的)传递到”animate”命令。
x: (as input) – 读取一个X 窗口展示
你也可以使用”x:” 来读取当前窗口显示,和”import命令中差不多的方式,不带选项,它和”import”命令的行为一样。使用左边的按钮选择窗口使用中间按钮来抓取一个副本或者一块区域。
例如:使用鼠标选择一个窗口,然后显示从其它窗口抓取的窗口(当抓取的窗口显示之后退出)
convert x: show:
警告:如果你抓取了一个未映射(图标化)的图像,或者在之上还有一个窗口,图像内同将包含一个空白区域或者重叠窗口的内容!!!因此要确保当抓取一个窗口时,窗口是在屏幕上是完全可见的,窗口名称使用’root’来抓取整个显示。
convert x:'root' full_screen_dump.jpg
或者使用Read Modifiers来抓取显示的特定区域。
convert x:'root[300x400+879+122]' part_screen_dump.jpg
给定窗口名称可以抓取特定的窗口,例如这可以抓取标题为’MailEd’的窗口。
convert x:'MailEd' window.jpg
但是这并不是很好使,因为通常你有许多有相同名字的窗口,或者窗口的名字不能决定。
更好的方式是使用”X Window ID”告诉IM所想要的确切窗口,”X Window ID”是X显示用来唯一地确定一个特定的窗口(或子窗口)的数字。
X Window ID是典型地使用”xwininfo”命令查找的,但是其它程序如”xdotool”, “xwit”和其它像”xprop”的工具,可以用来发现关于窗口的信息。例如:窗口级别、名称、标题、尺寸、位置、子窗口和窗口管理器的装饰。
例如,在所有标题或名称中找出有”Mozilla Firefox”的窗口。
xwininfo -root -all | grep "Mozilla Firefox"
然后,我可以从上面的输出中提取窗口的X Window ID。
在我的窗口管理器中是一个稍微复杂些的bash脚本,当我按下一个按钮,它就会自动获取当前焦点窗口的ID号,并捕获它的图像,然后在我当前目录中使用未来捕获的数量(结合以前捕获的数量)为PNG文件命名。
bash -c " id=$(xprop -root _NET_ACTIVE_WINDOW | sed 's/.* //') convert x:$id capture-tmp-$$.png num=$( ls capture-[0-9]*.png 2>/dev/null | sed -n '$ s/[^0-9]//gp' ) num=$( printf %03d $(expr $num + 1) ) mv capture-tmp-$$.png capture-$num.png "
大多数终端程序会告诉你在环境变量”WINDOWID”中,用来显示文本的X Window ID。因此,你从一个XTerm的命令行或Gnome Terminal来运行它,你将抓取当前终端窗口的一个副本。
convert x:$WINDOWID this_terminal.png
现在找点有趣的:在这里我抓取了当前终端的内容,在上面画一些东西,然后使用”display”将其画回到相同的终端窗口!
window=`xwininfo -children -id $WINDOWID |\
sed -n 's/^ *\(0x[^ ]*\).*/\1/p'`; \
window="${window:-$WINDOWID}"; \
convert x:$window -background black \
-draw 'fill black rectangle 40,40 160,160' \
-draw 'stroke red line 50,50 50,150 line 50,150 150,150' \
-draw 'fill lime circle 110,100 80,100' \
-draw 'stroke dodgerblue line 50,150 150,50' \
rose: -geometry +180+60 -composite \
png:- |\
display -window $window -
上述第一个命令是专为”XTerm”窗口,要求所显示的窗口是给定的”WINDOWID”的子窗口。如果没有发现子窗口,第二行将回落到”WINDOWID”的原始值,和”Gnome-Terminal”窗口的情况一样。
一旦使用的窗口被制定出,它将抓取、绘制和重建到终端窗口!并且即时图像将直接输出到当前的终端窗口。
下面是一个简单一些的例子,每次运行的时候将使窗口内容变暗,在一个实际的”xterm”窗口中运行一些次之后,你会发现在终端窗口中命令越旧,将变得更暗。
window=`xwininfo -children -id $WINDOWID |\
sed -n 's/^ *\(0x[^ ]*\).*/\1/p'`; \
window="${window:-$WINDOWID}"; \
convert x:$window -background black -colorize 20% png:- |\
display -window $window -
当我在自己的”xterm”窗口中重复上面的操作时,将有’capture’展示:
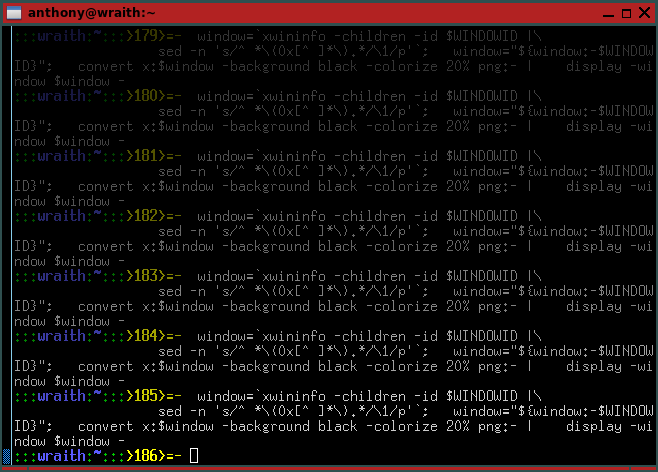
警告:尽管终端的内容被修改了,它只是暂时的。如果图标化、模糊化或者改变屏幕桌面,然后返回到终端,则修改的将会丢失,因为终端程序重画了窗口,清除修改。
上面的在”Gnome-Terminal”和”XTerm”中运行的不一样,因为前者每次滚动时都’re-draw’其窗口,”XTerm”s则不。
直接在各种窗口中直接显示图像和其它内容结果的Imagine IM脚本是一个较大的客户端程序的一部分。事实上多少postscript浏览器甚至是网页浏览器从特殊子程序中显示输出,换言之,它们有子程序接管并直接绘制到提供的子窗口。
进行尝试,然后通过邮件或IM Users Forum告诉我(或其他人)你得到的结果是什么。
图像格式的解码器和引用方法
解码器是处理图像输入和输出”format:”方面的动态库模块(通常以C语言编
写),也可以用来创建特殊用途的过滤器,可能需要安装被叫做引用库的外部程序库。
另一种类型的’Delegate’是告诉IM可以用来解码一些没有内置’coder’的图像格式的外部命令。最有名的’delegate’程序是允许IM读取、转换Postscript和PDF页为光栅图像的”ghostscript”。’delegate commands’对用户也非常有用,因为它允许你修改IM如何处理特殊类型的图像,或者提供另外的方法来读取和写入这些图像。
‘commands’本身被列在一个位于IM系统配置目录中名为”delegates.xml”的文件,但是也读取位于Linux/UNIX主目录的用于个人”.magick”子目录中的”delegates.xml”,用户需将’command delegates’放置在第二个文件中。
输入引用命令示例
比如,我可以在我的Linux/UNIX主目录的”.magick”子目录中以以下格式创建一个个人的”delegates.xml”文件:
<?xml version="1.0" encoding="UTF-8"?> <delegatemap> <delegate decode="flip" command="convert '%i' -flip 'miff:%o'"/> </delegatemap>
这是一个完整的’delegate’配置文件,但是只有中间行才是一个真正的引用,一个非常简单的命令,告诉IM如果看到有’.flip’后缀或者’flip:’格式前缀的图像,将调用上面的命令,来读取’flip’格式图像。
例如:
convert flip:tree.gif delegate_tree_flip.gif

在这个例子中,引用命令所做的是在原IM命令读取和处理图像之前,使用一个单独的IM “convert”命令来’flip’图像使之颠倒。
引用假设命令将理解给定的图像文件格式且将返回IM本身理解的任何图像文件格式(在例子中是 MIFF 图像文件格式)。
引用中的’%i’ 和 ‘%o’部分代表了这个命令将读取输入图像的副本或者读取’converted’输出的临时文件名,这些文件名是由IM生成的,位于临时目录中。这些临时文件名没有任何图像后缀,因此在必要的情况下在图像格式中加前缀是非常重要的。
这样做是出于安全,因为IM本身可能只读取数据流,而不是实际的文件。它也意味着辅助命令不需要处理这样的问题。
有一些另外的’%’替代像为中间临时文件的辅助临时文件名或者其它目的的内容。更多关于转义和其它引用选项的详细信息提供在IM安装的’system’ “delegate.xml”文件的顶端的注释中。
现在这个看起来似乎是相当愚蠢和琐碎的例子,但它主要意味着你可以使用一个辅助命令来转换任何数据文件到任何IM理解的图像。然后,IM将知道如何根据给定的图像后缀或者格式前缀,而不是所有的细节,来自动处理该数据类型。
许多这种类型的引用已经被添加到系统文件中,所以值得了解。
处于安全原因,个人的”delegates.xml”文件不会覆盖系统安装的”delegates.xml”文件的引用。你只能在你的主目录上的”.magick/delegates.xml”中添加新的引用格式,之后重复的引用将被忽略。
当然如果输入格式是内部已知的,则系统引用不会看它。
通常,你需要屏蔽任何用户的输入(特别是Web用户),因为你不希望用户在你不知道的情况下使用引用方法。
例如在IM v6.4.2-6中,一个”autotrace:’引用被添加到系统引用文件,将在读取任何输入图像的同时,运行”AutoTrace”命令。IM通过将输入图像转换为引用程序需要的PNG图像格式,通过引用过滤,然后读取作为结果的SVG,来产生原输入位图图像一个平滑边缘版本。见Raster to Vector Converter Example。
如果你想使用一个可以生产多个图像文件(如PNG)的转化器,你需要将所有单独的图像合并为像MIFF的单一多图像格式,因此IM可以从一个输出文件中读取多个图像。
IM有时会将多个引用程序串到一起来读取图像,例如,读取是一个图像的’HTML’页,它首先调用引用”html2ps”来将其转换为postscript,然后使用特殊的”ghostscript”程序引用来将生成的postscript文件转换为一系列的多个图像。
当然,由于复杂的相互作用、错误的安装和在引用程序中可能出现的漏洞,使用两个或更多的像这样的引用将产生其它问题,但是通常能够运行。
输出引用示例
当保存图像到IM不能直接理解的特定图像文件格式时,会采取相同的操作。
例如,将这个引用添加到你个人的”.magick/delegates.xml”文件,你可以告诉IM如何创建一个’.xyzzy’图像文件。
<delegate decode="gif" encode="xyzzy" command='mv "%i" "%o"'/>
当然,这只是快速拷贝一个GIF文件格式图像为TMP文件格式,但是这个命令可以是你喜欢的任何类型的图像转换器,脚本或者shell命令序列。
有了个人引用,IM可以创建’.xyzzy’图像,至少提供了一种方法。
convert rose: -negate rose.xyzzy identify rose.xyzzy
注意:上面的识别不理解’.xyzzy’后缀(没有提供输入引用),但是文件’magic’(文件本身中的识别字符串)告诉IM它实际上是一个GIF图像格式,因此IM将正确地处理它,而不需要特殊的输入引用或者解码器。
这就是’ImageMagick’的’MAGIC’部分。
运行外部命令
一个外部命令引用不仅可以用来从文件中转换图像或者转换图像到文件中,还可以作为在后台运行复杂命令的快速方式。这样的引用添加了一个”spawn=”True””属性,将启动命令,等待它删除输入图像,然后照常运行,留下命令在后台运行。
例如,”show” 和 “win”这两个输出引用都提供了显示IM”display”程序中命令的结果。
比如:
convert rose: label:rose -append show:
将追加一个标签到内置的玫瑰图像中并且在屏幕上显示,当运行引用已经读取了输入图像且删除了它(通常使用特殊的”ephemeral:”输入格式,见上),主要的前台进程将继续(和退出),留下’display’程序在后台运行,显示结果。
努力记住一个脚本的”display”命令或者你自己运行IM时编写的复杂命令所需的全部特殊选项将方便得多的。
我建议你看一看你的系统”delegate.xml”文件中的”show”运行引用。
引用方法列表
一个IM可以用来转换图像格式的外部引用的完整列表是从一个叫做”delegates.xml”和一个个人的”delegates.xml”文件中读取的(见下),如果你发现了这个文件,它使读取变得非常有趣。
但是,这个文件的格式非常复杂,我们就不在这里介绍了,虽然它在系统文件和在线用户手册(或ImageMagick安装目录的docs区中)都进行了解释
IM从这些文件中读取的引用和转换的简单总结可以使用以下打印出来:
convert -list delegate
 注意:一些在任何”delegates.xml”文件中声明的引用不会被列出来,如果它在引用条目中使用了’stealth=”True”‘选项来标记为特殊的外部引用。
注意:一些在任何”delegates.xml”文件中声明的引用不会被列出来,如果它在引用条目中使用了’stealth=”True”‘选项来标记为特殊的外部引用。
所有的引用都是可选的,且在特定的转换中,可以创建多个引用。如果一个引用不能用(故障或图像没有创建),IM将尝试下个引用,直到找到可以运行的,或者所有的引用都不能用,将产生错误来表明它不能读取那个图像。
Postscript 和PDF 引用
通过使用引用,ImageMagick可以利用外部程序来进行一些更复杂和特殊图像格式转换。
例如,尽管Postscript (PS:) 和 Encapsulated Postscript (EPS:)不能直接被ImageMagick写入,这些文件格式不能被IM读取。Postscript是一个完整的计算机语言且需要一个非常复杂的解释来创建图像。它远远超出了IM的范围来处理这种文件格式的读取。
为解决这个,IM寻找一个外部的叫做”ghostscript”的引用程序,来将PS 或 EPS格式文件转换为其它IM可以轻松读取的图像格式。
当然,这意味着如果你得到这样的错误:
转换:这种图像格式没有解码引用`…’
基本意味着IM不能找到合适的外部程序来转换你给定的图像格式为IM本省可以处理的图像格式,对Postscript图像,那通常意味着”ghostscript”没有安装,错误配置,或者在系统上的未知位置。
PDF/PS “ghostscript”引用是以特殊的格式在内部使用, IM内部检查postscript格式图像来尝试准确地决定如何通过给定的引用栅格化文件。
事实上,多个PS引用出现且由IM根据情况选定。例如ghostscript 装置使用的(’bmpsep8′ verses ‘pngalpha’)是根据”-colorspace RGB”是否预先设定了。
对PDF,我们使用’ps:color’引用而不是’ps:alpha’,因为’pngalpha’ ghostscript装置仅支持一对一的页面到图像的转换且PDF通常有多页。
直接引用格式转换(Taint)
引用系统也允许IM调用外部程序来将图像从一种格式转换为另一种格式,但是只有目标图像能被IM读取,且”convert”的结果是图像的一个’untainted’副本。
例如,如果你尝试将一个’Adobe Illustrator’文件(“.ai”)(Postscript的一种)为EPS(encapsulated postscript):
convert -density 300 map.ai map.eps
然后IM将把”map.ai”转换为IM理解的EPS文件(以”/tmp”),然后读取到内存(在使用’eps’引用之后),接下来将会发现实际上并不需要修改它(它仍然是’untainted’)。
因为图像没有发生任何变化,且已经转换为’eps’文件格式,IM将简化本身,然后直接复制生成的’eps’文件为”map.eps”。
也就是说,EPS文件将仅仅是原始的未经任何改变的Adobe Illustrator文件!
换言之,IM只使用其内部的引用来转换文件(重命名)。它本省从来不实际处理图像,因此,它还是一个纯矢量图像。
但是你可以强制IM实际上读取和写出图像,作为一个栅格,通过使用特殊的”-taint”操作符来标记它已被修改,而不需要实际上修改它,因此,这将使IM在encapsulated postscript中输出一个栅格化的图像数据。
convert -density 300 map.ai -taint map.eps
其它引用示例
修改Postscript引用为CMYK postscript见 Blog of John,
DCRaw 8位处理相机图像引用方法另一种读取8位完全处理的’raw’数码相机图像(CRW, CR2, NEF,等等)的引用的方法是:
<delegate decode="dcraw8" command='dcraw -v -w -O "%o" "%i"'/>
这将读取’raw’相机图像,然后将其转换为PNG文件格式(尽管你也可以很容易地添加一个’-T’标志和一个TIFF图像格式),输出的图像仍然是ImageMagick可读的。
加入这个引用可以在任何ImageMagick图像读取操作中(任何API,而不是仅仅命令行)简单地使用它,IM将处理所有的文件IO和清理。例如:
convert dcraw8:image.crw image.png
如果你不定义”dcraw”的执行文件路径,IM将围绕用户当前的PATH环境变量搜索程序,但是允许这个将产生安全问题。系统安装的引用通常定义了完整的命令路径。
见IM Users Forum Discussion中的注释。
使用’ffmpeg’进行视频解码器引用
例如,以下是由Mikko Koppanen在他的Mikko’s blog 网站中发表的一个引用方法。添加这个到你的个人的”.magick”目录中的”delegates.xml”文件中。
<delegate decode="ffmpeg" command="'ffmpeg' -i '%i' -y -vcodec png -ss %s -vframes 1 -an -f rawvideo '%o'" />
IM现在可以使用”ffmpeg”程序来从一个MPEG视频图像中解码帧。比如:
convert "ffmpeg:test1.mpg[40]" frame_40.png
真正大规模的图像处理
处理任何形式的大图像,使用ImageMagick的Q8版本将会更好,因为它比更高质量的Q16版本占用的内存少了一半。使用”identify -version”检查你的IM编译的Q级别。
对于中等大小的图像,你可以尝试使用”-limit”来增加处理限制(例如处理”-limit area 8192 -limit memory 8192″),来尽力避免IM将图像数据缓存到磁盘。但是你的系统有可能拒绝大的内存要求,仍然强制IM将图像缓存到磁盘(将慢近1000倍)。
你可以使用”-debug cache”来监视操作,来看IM是否在图像处理中使用了磁盘缓存。
同样见 IM Forum Discussion。
内存/磁盘管理
如果你打算处理一个真正大的图像,可能希望确定IM不会用尽电脑的内存,减慢其它程序的速度,可以简单地通过要求它立即使用临时运行磁盘文件。
例如,这是一个非常好的方法来在很长一段时间内处理一个非常大的图像,而不妨碍你使用计算机来进行其它操作。从根本上说,它强制IM将所有内容缓存到磁盘。
env MAGICK_TMPDIR=/data nice -5 \
convert -limit memory 32 -limit map 32 \
huge_9Gb_file.psd -scene 1 +adjoin layer_%d.png
当然,这假设”/data”有足够的文件和磁盘空间来处理图像的内存需求。
内存映射磁盘文件
如果你对相同的源图像执行多个操作,且也有大量的磁盘空间,你可以使用高代价创建但是几乎是零成本加载的 MPC image format 。
convert mybigassimage.jpg mybigassimage.mpc
convert mybigassimage.mpc -resize 50% resized.jpg
convert mybigassimage.mpc -rotate 90 rotated.jpg
...etc...
rm -f mybigassimage.mpc mybigassimage.cache
这将让你花费一个小的成本和内存占用来读取一个大的图像多次。
一个使用这种方法进行拼接的示例脚本可以在IM论坛中的Cut large image on tiles中找到。
从根本上说,MPC图像格式文件包含两个实际文件,一个报告的”.mpc”文件和一个图像直接内存页副本的”.cache”文件,当然,当你完成的时候,这两个文件都要删除。
这种方法被开发出来,使每次运行一个新的”convert”命令时,IM不需要重新解析图像格式和缓存图像到磁盘,而且,如果你只能访问输入图像的部分,每个命令不需要处理整个图像,而只是根据需要从缓存磁盘中读取那个部分。
如果你想处理图像的一个非常大的MPC副本,提取或 crop图像的一小块区域来供实际处理是一个好主意,这是因为对图像执行的任何操作,都将产生所生产结果一个新的在内存中的副本,因此最初的才将是一个非常好的主意。
如果你有内存,也可以尝试使用如’TMPFS’ 或 RamDisk ‘类型文件系统的memory disk’。但是要注意,填充这些类型的磁盘也将直接填充你的电脑内存。
尽管你可以使用上面的MPC方法从一个源图像裁剪各种区域来供进一步处理,还是需要以MPC格式读取或写出图像,且对大量图像来说还需要大量的时间。
IM也包含一个一个简单的称为”stream”管道处理器,这种程序有一组有限的操作,每次只能处理图像的一个扫描线(像素的行)。因此当以这种方式处理图像时,只需要足够的内存来存储像素的单个行。
比如,这允许你从一个非常大的图像中提取一个较小的区域来做进一步处理,而不需要首先读取整个图像,但是”stream”的输出是原始RGB图像值,所以建议做一些后期处理。
stream -map rgb -storage-type char -extract 600x400+1900+2900 image.png - |\
convert -depth 8 -size 600x400 rgb:- tileimage.png
输出没有保存到文件,但是可以直接继续处理较小的图像。例如:
stream -map rgb -storage-type char -extract 600x400+1900+2900 image.png - |\
convert -depth 8 -size 600x400 rgb:- ...more_processing_here... tile.png
这将只处理提取的600×400 像素图像,而不需要首先读取整个大的图像。
将许多小块图像合并到原图中
这个问题还没有被真正的回答。从根本上来说,IM没有提供一个实际重叠或追加多个小的拼接图在一起的方法。
但是并不是说这就不能完成,其中一个解决方案就是为流水线选项选择一个设计更合理的处理包。请参看下面的Using PbmPlus/NetPbm。
速度问题
Peter V peter.v@pv2c.com指出:以我的经验是使用”stream”来切割800MB PNM文件相较于使用MPC文件或使用”convert -crop”是最快的。
哪些格式可以运行:
Paul Heckbert指出:该流适合特定的文件格式(特别是JPEG),但是不是适合其它的像PSB等可能交叉存取的类型。
我认为这取决于特殊文件格式的’coder’是否提供像素逐行流支持,这可能是因为生成文件格式’coder’的程序没有时间运行,或需要’streaming’,在这种情况下,一个程序员关于图像文件格式更为熟悉的工作是可能需要完成’coder’模块。
像SVG或 WMV的矢量图像文件格式,或者一个由一些’delegate’预先处理的图像,比如数码相机图像文件格式,不可能是’streamed’,因为在图像中没有实际的像素,只有绘制的图像(线、多边形和渐变阴影色)
对于JPEG格式图像:
就像IM论坛讨论 Extract a region of an huge jpeg,你可以使用由JPEG Club开发的特殊的”jpegtran” and “jpegcrop”等JPEG程序,从一个JPEG图像中提取一个区域,而不需要解码数据。这是从一个JPEG图像到另一个JPEG图像的无损裁剪。
jpegtran -crop 100x100+0+0 -copy none huge.jpeg crop.jpg
左上的起点将被移到较小的8或16个,适当增加最终图像的大小,这是因为JPEG图像使用’frequency encoded blocks’,通常是8×8像素或16×16像素(由JPEG抽样因素确定,1 = 8 像素, 2 = 16 像素),如果进行了无损复制,这些模块需要被保存。
对于一个’+0+0’偏移量,已经是在适当的边界,因此上述的将产生一个精确的100×100像素裁剪。但是对其它偏移量,你需要对提取的区域进行一些最后的清理。例如:
jpegtran -crop 100x100+123+425 -copy none huge.jpeg crop.jpg
convert crop.jpg -gravity SouthEast -crop 100x100+0+0 +repage crop_fixed.png
对大量的图像使用PbmPlus/NetPbm
PbmPlus/NetPBM image processing tools方法 使用了一连串有着专门职能的单独工具。每个工具都设计为越简单和快速处理越好,只需要图像的原始数据和少量元数据(图像深度和尺寸)。
通过每个工具处理一个图像数据流,或者多个图像流来运行。每个工具处理每个图像,然后将图像传递到这个链上的下一个工具。每个工具可能只是读取了它所工作的一小块区域,通常只有单行或者像素的一个小的缓冲区,因此在处理大的图像时,内存占用非常小。
Pbmplus工具的最大的问题是图像都是从一个非常简约和未压缩的文件格式中转换而来或者转换为该格式。缺乏压缩不是一个问题,因为格式很少被实际保存,但是将从一个命令传递到下一个。然而文件格式不处理图像元数据,并且通常也不处理透明度。
但是当你处理非常大的图像时,这只是一个小的代价。
让我们来看一个纯PbmPlus例子:
tifftopnm INPUT.tif input.pam
pamcut input.pam part.pam
# process smaller "part.pam" image here
pamcomp -xoff= -yoff= - input.pam output.pam
pamtotiff output.pam OUTPUT.tif
“tifftopnm”将图像转换为图像数据流,和ImageMagick “stream”命令执行类似的工作。
“pamcut”等同于一个Crop Operation,且将从输入图像中摘取一个小的区域,而不是宽度或高度。你也可以指定从右或者底部来进行裁剪。且可以使用一个”stream”命令替代”convert,
中间部分,可以使用普通的ImageMagick来处理,或者如果你喜欢的话,也可以使用一系列PbmPlus等价工具,IM也可以保存小区域至TIF或者一些其他格式。
“pamcomp”将覆盖返回到源图像的PbmPlus版本的图像的修改部分。
问题是它是未知的(且未在手册中明确提及),如果”pamcomp” 使用逐行流转换来合并图像。有人可以验证使用大图像的情况吗?
另一方面是,”pamcomp”使用的是 Over Composition操作。这对没有透明度的图像没有任何问题,但是我们可能更想要Copy Composition的操作,它也替换重叠区域的透明度。这个的解决方法可能是一个预先准备的完全透明的画布,在这上面,所有修改的部分都将重叠了,另一中可能的方法是”pnmpaste”。
它也极有可能使用”pamdice” 和 “pamundice”来生成和合并可以由ImageMagick单独处理的一系列拼接图像,但是这是基于文件而非流的序列,意味着将占用大量的内存和磁盘空间。
如果一个生成和合并一连串拼接图像的方法可以开发出来将更好,则一个更常用的不需要使用临时文件的大量图像处理器可以开发出来。(见下)
图像流,视频序列
在一个论坛的讨论中,Reading Multiple Images,用户想处理由”ffmpeg”视频处理程序生成的多个PPM图像的’stream’,Pbmplus 图像可以简单的合并到一起来生成多个图像流。
问题是IM目前还不能允许你只从一个图像流中读取一个图像,进行处理,然后读取另一个单个图像,所有的IM命令总是读取整个图像流,然后关闭它,这对视频文件的处理是一个坏消息,因为你不会想每次都将整个视频读取到内存,或者使用一帧来处理视频。
一种解决方法是一个小的perl脚本,”process_ppm_pipeline”,将接受一个PPM图像流,且在每个图像上运行单独的”convert”命令。输出仍然是一系列生成了新的图像流的PPM图像。
For example read a video, and ‘flip’ every frame, one by one…
例如,读取一个视频且’flip’每一帧,一个接一个:
ffmpeg input.mpg -f image2pipe -vcodec ppm | pnmtopnm -plain |
process_ppm_pipeline -flip |
ffmpeg -f image2pipe -vcodec jpeg output.mpg
“pnmtopnm -plain”至关重要,因为脚本只处理ascii-PPM图像流,尽管更聪明时,它也可以用来处理二进制 Pbmplus图像流,或者甚至是MIFF 图像流,这样的工具也可以用来处理大量的大图像,如果你可以找到将图像分至tiles流,然后在最后重建大图像。
最后,我希望包含一些进程,通过这些进程你可以让编码器从多个图像文件流中读取和返回一个图像,而不需要关闭文件流,因此在之后另一个图像可以被读取。
VIPS 和 NIP,一个非IM的大量TIFF处理程序
Jenny Drake < jennydrake @ lineone.net >报告:你可能也想考虑非IM的”Vips” 和”nip”选项,它是由伦敦的国家肖像画廊开发的,初衷是为了用低规格的电脑来处理非常大的图像文件(通常TIFF)。”Vips”是潜在的引擎,”nip”则是图像用户界面,可在Linux, Windows及有时候在Mac上运行。

