最快的 Python 读取 Excel 方法
在 4 秒内读取50万行数据–我最近需要用 Python 来读取 Excel 文件,因此我测试了几种用 Python 读取 Excel 文件的方法,并对其进行了基准测试。

我没有任何数据来支持接下来的说法,但我相当肯定,Excel 是存储、操作,甚至是传递数据的最常见方式(!)。这就是为什么在 Python 中读取 Excel 的原因。我最近需要用 Python 来读取 Excel 文件,因此我测试了几种用 Python 读取 Excel 文件的方法,并对其进行了基准测试。
在本文中,我将比较几种从 Python 中读取 Excel 的方法。
我们要测试什么?
要比较用 Python 读取 Excel 文件的方法,我们首先需要确定要测量什么以及如何测量。
我们首先创建一个 25MB 的 Excel 文件,其中包含 500K 行和各种列类型:
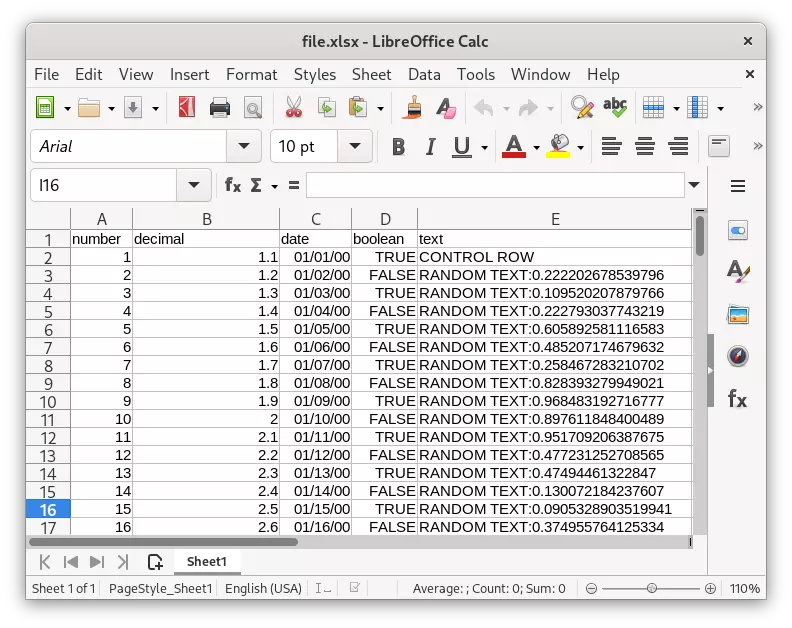
Excel 支持 xls 和 xlsx 两种文件格式。我们将使用较新的 xlsx 格式。
在基准测试中,我们将使用函数从 Excel 中导入数据并返回一个 Iterator :
def iter_excel(file: IO[bytes]) -> Iterator[dict[str, object]]:
# TODO...
我们返回一个Iterator ,以便逐行处理文件。这样就可以在处理文件时不在内存中存储整个文件,从而减少内存占用。我们将在基准测试中看到,这并不总是可行的。
为了生成 “干净 “的时序,我们在不进行任何实际处理的情况下迭代处理:
for row in iter_excel(file):
pass
这将使分析程序以最小的性能或内存开销进行全面评估。
速度
要测量的最明显的东西是时间,在 Python 中为性能目的测量时间的最准确的方法是使用 time.perf_counter:
import time
start = time.perf_counter()
for row in iter_excel(file): pass
elapsed = time.perf_counter() - start
我们启动计时器,遍历整个循环并计算所耗时间。
数据类型
一些类型(如 parquet 和 avro)以自描述而著称,它们将模式保存在文件中,而其他格式(如 CSV)则以不保存任何有关其所存储数据的信息而臭名昭著。
Excel 可以看作是一种存储了内容类型信息的格式–有日期单元格、数字单元格、小数单元格和其他单元格,因此在从 Excel 加载数据时,以预期的类型接收数据是非常有用的。这对于日期(格式可能不明确或未知)或包含电话号码或邮政编码等数字的字符串等类型尤其有用。在这些情况下,尝试嗅探类型可能会导致不正确的结果(由于修剪前导零、假定不正确的格式等)。
公平地说,有些人可能会说,在将数据加载到系统时,你应该了解其模式,因此对某些人来说,保留类型可能不是一个严格的要求。
正确性
为了测试导入过程的正确性,我们在 Excel 文件的开头加入了一个控制行。我们将使用该控制行作为参考,以确保数据导入正确:
# Test correctness of imported data using a control row
for key, expected_value in (
('number', 1),
('decimal', 1.1),
('date', datetime.date(2000, 1, 1)),
('boolean', True),
('text', 'CONTROL ROW'),
):
try:
value = control_row[key]
except KeyError:
print(f' "{key}" missing')
continue
if type(expected_value) != type(value):
print(f' "{key}" expected type "{type(expected_value)}" received type "{type(value)}"')
elif expected_value != value:
print(f' "{key}" expected value "{expected_value}" received "{value}"')
else:
print(f' "{key}"')
我们将在每次基准测试后运行该测试,以确保控制行中存在所有预期键,并且类型和值与我们预期的一致。
用 Python 读取 Excel
现在,我们有了一个示例文件,一种测试文件内容的方法,而且我们已经定义了要测量的内容–我们已经准备好导入一些数据了!
使用 Pandas 读取 Excel
Pandas 是 Python 的数据分析库,是用 Python 处理与数据有关的任何问题的首选,因此是一个很好的开始。
使用 Pandas 读取 Excel 文件:
import pandas
def iter_excel_pandas(file: IO[bytes]) -> Iterator[dict[str, object]]:
yield from pandas.read_excel(file).to_dict('records')
只需将两条命令串联起来,就能从 Excel 文件中获取字典列表。这是结果中的一行:
>>> with open('file.xlsx', 'rb') as f:
... rows = iter_excel_pandas(f)
... row = next(rows)
... print(row)
...
{'boolean': True,
'date': Timestamp('2000-01-01 00:00:00'),
'decimal': 1.1,
'number': 1,
'text': 'CONTROL ROW'}
一眼就能看出日期不是 datetime.date 而是 pandas Timestamp。其他部分看起来都没问题。如果时间戳是个问题,并且坚持使用 datetime.date 格式,可以为 read_excel 提供一个转换函数:
import pandas
def iter_excel_pandas(file: IO[bytes]) -> Iterator[dict[str, object]]:
yield from pandas.read_excel(file, converters={
'date': lambda ts: ts.date(),
}).to_dict('records')
转换器接受 pandas 时间戳,并将其转换为 datetime.date 格式。这是使用自定义转换器的控制行:
{
'number': 1,
'decimal': 1.1,
'date': datetime.date(2000, 1, 1),
'boolean': True,
'text': 'CONTROL ROW',
}
如果你使用 pandas 从 Excel 中读取数据,那么假设你也想继续使用 pandas 进行分析也不无道理,因此我们将接受时间戳作为我们基准的有效类型。
接下来,在大型 Excel 文件上运行基准:
iter_excel_pandas
elapsed 32.98058952600695
"number"
"decimal"
"date" expected type "<class 'datetime.date'>" received type "<class 'pandas._libs.tslibs.timestamps.Timestamp'>"
"boolean"
"text"
导入耗时约 32 秒。日期字段的类型是 pandas Timestamp,而不是 datetime.date,不过没关系。
使用 Tablib 读取 Excel
Tablib 是 Python 中最流行的库之一,用于导入和导出各种格式的数据。它最初是由流行的 requests 库的创建者开发的,因此同样注重开发者的体验和人体工程学。
要安装 Tablib,请执行以下命令:
$ pip install tablib
使用 tablib 读取 Excel 文件:
import tablib
def iter_excel_tablib(file: IO[bytes]) -> Iterator[dict[str, object]]:
yield from tablib.Dataset().load(file).dict
只需一行代码,该库就能完成所有繁重的工作。
在继续执行基准测试之前,我们先看看第一行的结果:
>>> with open('file.xlsx', 'rb') as f:
... rows = iter_excel_tablib(f)
... row = next(rows)
... print(row)
...
OrderedDict([('number', 1),
('decimal', 1.1),
('date', datetime.datetime(2000, 1, 1, 0, 0)),
('boolean', True),
('text', 'CONTROL ROW')])
OrderedDict 是 Python dict 的子类,带有一些用于重新排列字典顺序的附加方法。它定义在内置的collections模块中,当你请求一个 dict 时,tablib 返回的就是它。由于 OrderedDict 是 dict 的子类,而且定义在内置模块中,我们并不在意,并认为它很适合我们的目的。
现在开始对大型 Excel 文件进行基准测试:
iter_excel_tablib
elapsed 28.526969947852194
"number"
"decimal"
"date" expected type "<class 'datetime.date'>" received type "<class 'datetime.datetime'>"
"boolean"
"text"
使用 tablib 导入耗时 28 秒,比 pandas(32 秒)快。日期单元格返回的是 datetime.datetime 而不是 datetime.date,这并非不合理。
让我们看看能否进一步缩短时间。
使用 Openpyxl 读取 Excel
Openpyxl 是一个用于在 Python 中读写 Excel 文件的库。与 Tablib 不同,Openpyxl 专门用于 Excel,不支持任何其他文件类型。事实上,在读取 xlsx 文件时,tablib 和 pandas 都在内部下使用 Openpyxl。也许这种专业化会带来更好的性能。
要安装 openpyxl,请执行以下命令:
$ pip install openpyxl
使用 openpyxl 读取 Excel 文件:
import openpyxl
def iter_excel_openpyxl(file: IO[bytes]) -> Iterator[dict[str, object]]:
workbook = openpyxl.load_workbook(file)
rows = workbook.active.rows
headers = [str(cell.value) for cell in next(rows)]
for row in rows:
yield dict(zip(headers, (cell.value for cell in row)))
这次我们要写的代码更多一些,让我们来分解一下:
- 从打开的文件中加载工作簿:函数 load_workbook 同时支持文件路径和可读流。在本例中,我们对打开的文件进行操作。
- 获取活动工作表:Excel 文件可以包含多个工作表,我们可以选择读取哪个工作表。在本例中,我们只有一张工作表。
- 构建页眉列表:Excel 文件的第一行包含页眉。要将这些页眉作为字典的键,我们需要读取第一行并生成页眉列表。
- 返回结果:openpyxl 使用的单元格类型包含值和一些元数据。这对其他用途很有用,但我们只需要值。要访问单元格的值,我们使用 cell.value。
这就是第一行结果的样子:
>>> with open('file.xlsx', 'rb') as f:
... rows = iter_excel_openpyxl(f)
... row = next(rows)
... print(row)
{'boolean': True,
'date': datetime.datetime(2000, 1, 1, 0, 0),
'decimal': 1.1,
'number': 1,
'text': 'CONTROL ROW'}
看起来很有希望!在大文件上运行基准测试:
iter_excel_openpyxl
elapsed 35.62
"number"
"decimal"
"date" expected type "<class 'datetime.date'>" received type "<class 'datetime.datetime'>"
"boolean"
"text"
使用 openpyxl 导入大型 Excel 文件耗时约 35 秒,比 Tablib(28 秒)和 pandas(32 秒)长。
在文档中快速搜索后,我们发现了标题为 “性能 “的章节。在这一节中,openpyxl 介绍了 “优化模式”,可以在读写文件时加快速度:
import openpyxl
def iter_excel_openpyxl(file: IO[bytes]) -> Iterator[dict[str, object]]:
workbook = openpyxl.load_workbook(file, read_only=True)
rows = workbook.active.rows
headers = [str(cell.value) for cell in next(rows)]
for row in rows:
yield dict(zip(headers, (cell.value for cell in row)))
工作表现在以 “只读 “模式加载。由于我们只想读取内容而不想写入,所以这种情况是可以接受的。让我们再次运行基准测试,看看它是否会影响结果:
iter_excel_openpyxl
elapsed 24.79
"number"
"decimal"
"date" expected type "<class 'datetime.date'>" received type "<class 'datetime.datetime'>"
"boolean"
"text"
在 “只读 “模式下打开文件的时间从 35 秒缩短到 24 秒,比 tablib(28 秒)和 pandas(32 秒)更快。
使用 LibreOffice 读取 Excel
我们现在已经用尽了将 Excel 导入 Python 的传统和显而易见的方法。我们使用了指定的顶级库,并取得了不错的结果。现在是跳出框框思考的时候了。
LibreOffice 是其他办公套件的免费开源替代品。LibreOffice 可以处理 xls 和 xlsx 文件,还包含一个无头模式和一些有用的命令行选项:
$ libreoffice --help
LibreOffice 7.5.8.2 50(Build:2)
Usage: soffice [argument...]
argument - switches, switch parameters and document URIs (filenames).
...
LibreOffice 命令行选项之一是在不同格式之间转换文件。例如,我们可以使用 libreoffice 将 xlsx 文件转换为 csv 文件:
$ libreoffice --headless --convert-to csv --outdir . file.xlsx
convert file.xlsx -> file.csv using filter: Text - txt - csv (StarCalc)
$ head file.csv
number,decimal,date,boolean,text
1,1.1,01/01/2000,TRUE,CONTROL ROW
2,1.2,01/02/2000,FALSE,RANDOM TEXT:0.716658989024692
3,1.3,01/03/2000,TRUE,RANDOM TEXT:0.966075283958641
不错!让我们用 Python 将其拼接起来。我们首先将 xlsx 文件转换为 CSV,然后将 CSV 导入 Python:
import subprocess, tempfile, csv
def iter_excel_libreoffice(file: IO[bytes]) -> Iterator[dict[str, object]]:
with tempfile.TemporaryDirectory(prefix='excelbenchmark') as tempdir:
subprocess.run([
'libreoffice', '--headless', '--convert-to', 'csv',
'--outdir', tempdir, file.name,
])
with open(f'{tempdir}/{file.name.rsplit(".")[0]}.csv', 'r') as f:
rows = csv.reader(f)
headers = list(map(str, next(rows)))
for row in rows:
yield dict(zip(headers, row))
让我们来分析一下:
- 创建一个用于存储 CSV 文件的临时目录:使用内置的 tempfile 模块创建一个临时目录,完成后会自动清理。理想情况下,我们希望将特定文件转换为内存中的类文件对象,但 libreoffice 命令行不提供转换为特定文件的方法,只能转换为目录。
- 使用 libreoffice 命令行将文件转换为 CSV:使用内置子进程模块执行操作系统命令。
- 读取生成的 CSV:打开新创建的 CSV 文件,使用内置的 csv 模块进行解析并生成 dicts。
这就是第一行结果的样子:
>>> with open('file.xlsx', 'rb') as f:
... rows = iter_excel_libreoffice(f)
... row = next(rows)
... print(row)
{'number': '1',
'decimal': '1.1',
'date': '01/01/2000',
'boolean': 'TRUE',
'text': 'CONTROL ROW'}
我们立即发现,我们丢失了所有类型信息–所有值都是字符串。
让我们运行基准测试,看看这样做是否值得:
iter_excel_libreoffice
convert file.xlsx -> file.csv using filter : Text - txt - csv (StarCalc)
elapsed 15.279242266900837
"number" expected type "<class 'int'>" received type "<class 'str'>"
"decimal" expected type "<class 'float'>" received type "<class 'str'>"
"date" expected type "<class 'datetime.date'>" received type "<class 'str'>"
"boolean" expected type "<class 'bool'>" received type "<class 'str'>"
"text"
老实说,这比我预想的要快!使用 LibreOffice 将文件转换为 CSV,然后加载它只用了 15 秒,比 pandas(35 秒)、tablib(28 秒)和 openpyxl(24 秒)都要快。
在将文件转换为 CSV 时,我们确实丢失了类型信息,如果还需要转换类型,很可能需要更多时间(序列化可能很慢,你知道的)。但总的来说,这不失为一个好选择!
使用 DuckDB 读取 Excel
既然我们已经走上了使用外部工具的道路,为什么不给新来的孩子一个竞争的机会呢?
DuckDB 是一个 “进程内 SQL OLAP 数据库管理系统”。这段描述并没有让人立即明白 DuckDB 为什么在这种情况下有用,但它确实有用。DuckDB 擅长数据移动和格式转换。
要安装 DuckDB Python API,请执行以下命令:
$ pip install duckdb
使用 Python 中的 duckdb 读取 Excel 文件:
import duckdb
def iter_excel_duckdb(file: IO[bytes]) -> Iterator[dict[str, object]]:
duckdb.install_extension('spatial')
duckdb.load_extension('spatial')
rows = duckdb.sql(f"""
SELECT * FROM st_read(
'{file.name}',
open_options=['HEADERS=FORCE', 'FIELD_TYPES=AUTO'])
""")
while row := rows.fetchone():
yield dict(zip(rows.columns, row))
让我们来分析一下:
- 安装并加载
spatial扩展:要使用 duckdb 从 Excel 中导入数据,需要安装spatial扩展。这有点奇怪,因为spatial扩展用于地理操作,但这正是它想要的。 - 查询文件:直接使用 duckdb 全局变量执行查询时,默认情况下会使用内存数据库,类似于使用 :memory: 选项的 sqlite。要实际导入 Excel 文件,我们使用 st_read 函数,并将文件路径作为第一个参数。在函数选项中,我们将第一行设置为标题,并激活自动检测类型的选项(这也是默认选项)。
- 构建结果遍历每一行,并使用每一行的标题和值列表构建 dict。
这就是使用 DuckDB 导入 Excel 文件后第一行的样子:
>>> with open('file.xlsx', 'rb') as f:
... rows = iter_excel_duckdb(f)
... row = next(rows)
... print(row)
{'boolean': True,
'date': datetime.date(2000, 1, 1),
'decimal': 1.1,
'number': 1,
'text': 'CONTROL ROW'}
现在,我们有了使用 DuckDB to Python 读取 Excel 文件的过程,让我们看看它的性能如何:
iter_excel_duckdb
elapsed 11.36
"number"
"decimal"
"date"
"boolean"
"text"
首先,我们在类型方面取得了胜利!DuckDB 能够正确检测所有类型。此外,DuckDB 的计时时间仅为 11 秒,这让我们更接近一位数的计时时间!
在这个实现过程中,有一件事困扰着我,那就是尽管我尽了最大努力,还是无法使用 duckdb.sql 函数的文件名参数。使用字符串连接生成 SQL 很危险,容易被注入,应尽可能避免。
为了解决这个问题,我尝试使用 duckdb.execute 代替 duckdb.sql,在这种情况下,它似乎可以接受参数:
import duckdb
def iter_excel_duckdb_execute(file: IO[bytes]) -> Iterator[dict[str, object]]:
duckdb.install_extension('spatial')
duckdb.load_extension('spatial')
conn = duckdb.execute(
"SELECT * FROM st_read(?, open_options=['HEADERS=FORCE', 'FIELD_TYPES=AUTO'])",
[file.name],
)
headers = [header for header, *rest in conn.description]
while row := conn.fetchone():
yield dict(zip(headers, row))
这里有两个主要区别:
- 使用 duckdb.execute 而不是 duckdb.sql:使用
execute,我可以将文件名作为参数,而不是使用字符串连接。这样更安全。 - 构建头文件:根据 API 参考,duckdb.sql 返回一个 DuckDBPyRelation,而 duckdb.execute 返回一个 DuckDBPyConnection。为了从连接对象中生成标头列表,我无法像以前那样访问 .列,所以我不得不查看连接的 description 属性,我想它描述了当前的结果集。
使用新函数运行基准测试得到了一些有趣的结果:
iter_excel_duckdb_execute
elapsed 5.73
"number" expected type "<class 'int'>" received type "<class 'str'>"
"decimal" expected type "<class 'float'>" received type "<class 'str'>"
"date" expected type "<class 'datetime.date'>" received type "<class 'str'>"
"boolean" expected type "<class 'bool'>" received type "<class 'str'>"
"text"
通过execute,我们只用了 5.7 秒就吞下了文件–这比上次尝试快了一倍,但我们丢失了类型。由于缺乏使用 DuckDB 的知识和经验,我只能假设构建关系并将其转换为正确的类型会产生一些开销。
在继续讨论其他选项之前,我们先来看看预加载和安装扩展是否会带来显著的不同:
import duckdb
+duckdb.install_extension('spatial')
+duckdb.load_extension('spatial')
+
def iter_excel_duckdb_execute(file: IO[bytes]) -> Iterator[dict[str, object]]:
- duckdb.install_extension('spatial')
- duckdb.load_extension('spatial')
rows = duckdb.execute(
"SELECT * FROM st_read(?, open_options=['HEADERS=FORCE', 'FIELD_TYPES=AUTO'])",
多次执行函数:
iter_excel_duckdb_execute
elapsed 5.28
elapsed 5.69
elapsed 5.28
预加载扩展程序对时间的影响不大。
让我们看看取消自动类型检测是否有影响:
duckdb.load_extension('spatial')
def iter_excel_duckdb_execute(file: IO[bytes]) -> Iterator[dict[str, object]]:
conn = duckdb.execute(
- "SELECT * FROM st_read(?, open_options=['HEADERS=FORCE', 'FIELD_TYPES=AUTO'])",
+ "SELECT * FROM st_read(?, open_options=['HEADERS=FORCE', 'FIELD_TYPES=STRING'])",
[file.name],
)
headers = [header for header, *rest in conn.description]
多次执行函数:
iter_excel_duckdb_execute
elapsed 5.80
elapsed 7.21
elapsed 6.45
取消自动类型检测似乎也没有对时间产生明显影响。
使用 Calamine 读取 Excel
近年来,Python 的每一个性能问题似乎最终都能用另一种语言来解决。作为一名 Python 开发人员,我认为这真是一件幸事。这意味着我可以继续使用我习惯的语言,并享受其他语言带来的性能优势!
Calamine 是一个纯 Rust 库,用于读取 Excel 和 OpenDocument 电子表格文件。要安装 calamine 的 Python 绑定 Python-calamine,请执行以下命令:
$ pip install python-calamine
使用 Python 中的 calamine 读取 Excel 文件:
import python_calamine
def iter_excel_calamine(file: IO[bytes]) -> Iterator[dict[str, object]]:
workbook = python_calamine.CalamineWorkbook.from_filelike(file) # type: ignore[arg-type]
rows = iter(workbook.get_sheet_by_index(0).to_python())
headers = list(map(str, next(rows)))
for row in rows:
yield dict(zip(headers, row))
再次执行相同的程序–加载工作簿、选择工作表、从第一行获取页眉、遍历结果并从每一行构建一个 dict。
这就是第一行的样子:
>>> with open('file.xlsx', 'rb') as f:
... rows = iter_excel_calamine(f)
... row = next(rows)
... print(row)
{'boolean': True,
'date': datetime.date(2000, 1, 1),
'decimal': 1.1,
'number': 1.0,
'text': 'CONTROL ROW'}
运行基准:
iter_excel_calamine
elapsed 3.58
"number" expected type "<class 'int'>" received type "<class 'float'>"
"decimal"
"date"
"boolean"
"text"
这是一个巨大的飞跃!使用 python-calamine 处理整个文件只用了 3.5 秒,是目前最快的!这里唯一的红点是因为我们的整数被解释成了浮点数,这并不是完全不合理的。
经过仔细研究,我发现 python-calamine 的唯一问题是它无法以迭代器的形式生成结果。CalamineWorkbook.from_filelike 函数会将整个数据集加载到内存中,而这取决于文件的大小,这可能是个问题。Python 绑定库的作者向我指出了底层绑定库 pyo3 中的这个问题,它阻止了 Python 对 Rust 结构的迭代。
结果摘要
以下是使用 Python 读取 Excel 文件的方法汇总:
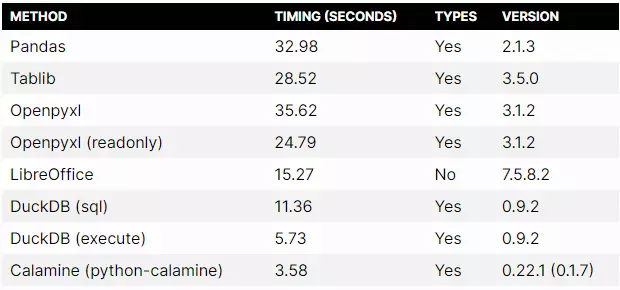
那么您应该使用哪个库呢?在 Python 中选择处理 Excel 文件的库时,除了速度之外,还有一些额外的考虑因素:
- 写入能力:我们测试了读取 Excel 的方法,但有时也需要生成 Excel 文件。我们测试过的一些库不支持写入。例如,Calamine 不能写 Excel 文件,只能读取。
- 其他格式:系统可能需要加载和生成 Excel 之外的其他格式文件。一些库(如 pandas 和 Tablib)支持多种其他格式,而 Calamine 和 openpyxl 仅支持 Excel。
基准测试的完整源代码可在此软件仓库中获取。

本文文字及图片出自 Fastest Way to Read Excel in Python,由 WebHek 分享。
