




2025年7月14日 Cloudflare 1.1.1.1 宕机事件解析
2025年7月14日,Cloudflare对服务拓扑结构进行了调整,导致1.1.1.1边缘节点出现服务中断,使用1.1.1.1公共DNS解析器的客户遭遇了62分钟的停机时间,同时网关DNS服务也出现了间歇性性能下降。
Cloudflare的1.1.1.1解析器服务自UTC时间21:52起无法访问,直至UTC时间22:54恢复。全球绝大多数1.1.1.1用户均受到影响。对于许多用户而言,无法通过1.1.1.1解析器解析域名意味着基本上所有互联网服务均不可用。此次故障可在Cloudflare Radar上观察到。
此次故障是由于用于维护向互联网广播Cloudflare IP地址的基础设施的遗留系统配置错误所致。
这是一次全球性故障。在故障期间,Cloudflare的1.1.1.1解析器在全球范围内不可用。
对此故障我们深表歉意。根本原因是内部配置错误,而非攻击或BGP劫持所致。在本篇博客中,我们将探讨此次故障的具体情况、发生原因,以及我们正在采取的措施以确保此类事件不再发生。

背景
Cloudflare 于 2018 年推出了1.1.1.1公共 DNS 解析器服务。自发布以来,1.1.1.1 已成为最受欢迎的 DNS 解析器 IP 地址之一,且对所有人免费开放。
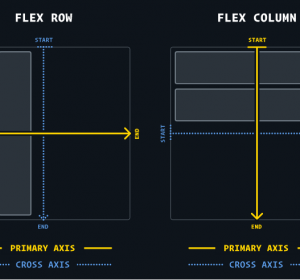
Cloudflare 的几乎所有服务均通过一种名为 anycast 的路由方法向互联网提供,这是一种广为人知的技术,旨在让热门服务的流量能够在互联网上的多个不同位置进行分发,从而提升容量和性能。这是确保我们能够全球管理流量的最佳方式,但也意味着该地址空间的广告问题可能导致全球性服务中断。
Cloudflare向互联网宣布这些Anycast路由,以便发往这些地址的流量被路由至Cloudflare数据中心,从而从多个不同地点提供服务。大多数Cloudflare服务均实现全球覆盖,例如1.1.1.1公共DNS解析器,但部分服务会针对特定区域进行限制。
这些服务属于我们的数据本地化套件(DLS),允许客户以多种方式配置Cloudflare,以满足不同国家和地区合规性要求。Cloudflare 管理这些不同要求的一种方式是确保正确服务的 IP 地址仅在需要的位置可通过互联网访问,从而确保您的流量在全球范围内得到正确处理。每个特定服务都有对应的“服务拓扑结构”——即该服务的流量应仅路由至特定位置集。
6 月 6 日,在为未来 DLS 服务准备服务拓扑结构的发布过程中,引入了一个配置错误:与 1.1.1.1 解析器服务相关的前缀意外地与 intended for the new DLS service 的前缀一起被包含在内。该配置错误在生产网络中处于休眠状态,因为新的 DLS 服务尚未投入使用,但它为 7 月 14 日的故障奠定了基础。由于生产网络没有立即发生变化,因此没有对最终用户造成影响,而且由于没有影响,也没有触发警报。
事件时间线
| 时间(UTC) | 事件 |
| 2025-06-06 17:38 | 问题引入 – 无影响
对一个尚未投入生产的DLS服务进行了配置更改。此次配置更改意外包含了对 1.1.1.1 解析服务(Resolver)的引用,进而涉及与该解析服务相关的前缀。 此次更改未导致网络配置变更,因此 1.1.1.1 解析服务的路由未受影响。 由于流量未发生变化,未触发任何警报,但该配置错误在未来版本中仍处于潜伏状态。 |
| 2025-07-14 21:48 | 影响开始
对同一 DLS 服务进行了配置更改。该更改将一个测试位置附加到非生产服务;该位置本身未启用,但该更改触发了全球网络配置的刷新。 由于之前配置错误将 1.1.1.1 解析器的 IP 地址与我们的非生产服务关联,因此在更改非生产服务配置时,这些 1.1.1.1 IP 地址被意外包含在内。 1.1.1.1解析器的前缀开始从全球生产环境的Cloudflare数据中心中撤销。 |
| 2025-07-14 21:52 | 指向1.1.1.1解析器服务的DNS流量开始在全球范围内下降 |
| 2025-07-14 21:54 | 相关但非因果事件:由于 Cloudflare 撤销路由,导致 1.1.1.0/24 的 BGP 源劫持暴露。此事件 并非 服务故障的原因,而是一个与之无关的问题,因该前缀被 Cloudflare 撤销而突然显现。 |
| 2025-07-14 22:01 | 影响检测到
1.1.1.1 解析器的内部服务健康警报开始触发 |
| 2025-07-14 22:01 | 事件宣告 |
| 2025-07-14 22:20 | 修复部署
已启动回滚操作以恢复先前配置。为加速服务全面恢复,手动触发的操作在测试环境中验证后方可执行。 |
| 2025-07-14 22:54 | 影响结束
解析器警报已清除,解析器前缀的 DNS 流量恢复至正常水平 |
| 2025-07-14 22:55 | 事件解决 |
影响
通过1.1.1.1解析器服务访问Cloudflare的任何流量均受到影响。这些地址对应的路由上的流量也受到影响。
1.1.1.0/24
1.0.0.0/24
2606:4700:4700::/48
162.159.36.0/24
162.159.46.0/24
172.64.36.0/24
172.64.37.0/24
172.64.100.0/24
172.64.101.0/24
2606:4700:4700::/48
2606:54c1:13::/48
2a06:98c1:54::/48
当影响开始时,我们观察到通过 UDP、TCP 和 DNS over TLS (DoT) 的查询量立即大幅下降。大多数用户将 1.1.1.1、1.0.0.1、2606:4700:4700::1111 或 2606:4700:4700::1001 配置为其 DNS 服务器。以下是各协议的查询速率及其在事件中的受影响情况:

值得注意的是,DoH(DNS-over-HTTPS) 流量保持相对稳定,因为大多数 DoH 用户通过域名 cloudflare-dns.com 访问公共 DNS 解析器,而非通过 IP 地址。由于 cloudflare-dns.com 使用了一组不同的 IP 地址,DoH 服务仍可正常使用,流量也基本未受影响。部分通过 UDP 传输的 DNS 流量(同样使用了不同 IP 地址)也基本未受影响。
随着对应的前缀被撤销,发往这些地址的流量无法到达 Cloudflare。我们可以在 1.1.1.0/24 的 BGP 公告时间轴中看到这一点:

上图显示了1.1.1.0/24在全球范围内的BGP撤销和重新公告的时间线
在查看被撤销IP的查询率时,可以观察到在影响窗口期间几乎没有流量到达。当在UTC时间22:20应用初始修复时,可以观察到流量的大幅激增,随后又再次下降。这一激增是由于客户端重新尝试查询所致。当我们重新宣布撤销的前缀时,查询再次能够到达Cloudflare。直到UTC时间22:54,所有位置的路由才恢复,流量也基本恢复到正常水平。


错误的技术描述及其发生原因
1.1.1.1 解析服务故障
如上所述,6月6日的一次配置更改导致了预生产环境中DLS服务的拓扑结构出现错误。7月14日,对该服务进行了第二次更改:为预生产DNS服务的拓扑结构添加了一个离线数据中心位置,以便进行内部测试。此次变更触发了相关路由的全球配置刷新,此时之前配置错误的影响开始显现。1.1.1.1解析器前缀的服务拓扑从所有位置缩减至单一离线位置。此举导致所有1.1.1.1前缀在全球范围内立即撤销。
随着指向 1.1.1.1 的路由被撤销,1.1.1.1 服务本身也变得不可用。警报触发,并宣布了此次事件。
技术调查与分析
Cloudflare 管理服务拓扑的方式经过了长期优化,目前由一个遗留系统和一个战略系统组成,两者保持同步。Cloudflare的IP范围目前在这些系统中被绑定和配置,这些系统决定了IP范围应在边缘网络中宣布的位置(即数据中心位置)。传统方法是通过硬编码明确列出数据中心位置并将其与特定前缀关联,但这种方法容易出错,因为(例如)启用新数据中心需要更新并一致同步多个列表。该模型还存在一个重大缺陷,即配置更新未遵循渐进式部署方法:尽管此次发布经过了多位工程师的同行评审,但变更并未在部署到所有 Cloudflare 数据中心前经历一系列金丝雀部署。我们的新方法是无需硬编码IP地址即可描述服务拓扑,这更有利于扩展至新地点和客户场景,同时支持分阶段部署模型,使变更可通过健康监测逐步传播。在两种方法的迁移过程中,我们需要同时维护两个系统并同步数据,具体流程如下:

DNS解析器于22:01触发初始警报,显示查询、代理和数据中心故障。在调查警报时,我们发现指向解析器前缀的流量急剧下降,且不再被我们的边缘数据中心接收。内部我们使用BGP控制路由广告,发现服务器上的解析器路由完全缺失。
一旦我们的配置错误被揭露且Cloudflare系统从路由表中撤销了这些路由,所有1.1.1.1路由本应完全从全球互联网路由表中消失。然而,1.1.1.0/24前缀并未如此。相反,我们从Cloudflare Radar收到报告,称Tata Communications India(AS4755)开始广告1.1.1.0/24:从路由系统角度看,这与前缀劫持完全一致。在排查路由问题时看到这一情况令人意外,但需明确指出:此次BGP劫持并非导致服务中断的原因。我们正在与塔塔通信公司进一步沟通。
恢复1.1.1.1服务
我们于UTC时间22:20恢复了之前的配置。几乎立即,我们开始重新广告之前从路由器中撤回的BGP前缀,包括1.1.1.0/24。这将1.1.1.1的流量水平恢复到事件发生前的约77%。然而,在撤回期间,由于拓扑结构的改变,大约23%的边缘服务器集群已被自动重新配置以移除所需的IP绑定。要恢复这些配置,这些服务器需要通过我们的变更管理系统进行重新配置,而该系统默认情况下并非即时完成,以确保安全。
恢复IP绑定通常需要一定时间,因为各地点的网络设计需在数小时内逐步更新。我们采用分阶段部署方式,而非一次性在所有节点实施,以避免引入额外影响。然而,鉴于此次事件的严重性,我们在测试地点验证变更后加速了修复方案的部署,以尽可能快速且安全地恢复服务。正常流量水平于UTC时间22:54恢复。
补救措施与后续步骤
我们高度重视此类事件,并充分认识到此次事件的影响。尽管该具体问题已得到解决,但我们已识别出若干可采取的措施,以减轻未来发生类似问题的风险。基于此次事件,我们正在实施以下计划:
分阶段部署地址: 现有组件未采用渐进式分阶段部署方法。Cloudflare将逐步淘汰这些系统,以实现现代渐进式和健康监控的部署流程,从而在分阶段过程中更早地发现问题并相应地回滚。
淘汰旧系统:目前我们处于一个过渡阶段,当前组件和旧组件需要同时更新,因此我们将逐步迁移地址系统,远离此类高风险的部署方法。我们将加速淘汰旧系统,以提升文档规范和测试覆盖率的标准。
结论
Cloudflare 的 1.1.1.1 DNS 解析服务因内部配置错误而受到影响。
我们对此次事件给客户带来的干扰深表歉意。我们正在积极实施这些改进措施,以确保未来系统稳定性并防止此类问题再次发生。
Cloudflare 的连接云可保护 整个企业网络,帮助客户高效构建 互联网规模的应用程序,加速任何 网站或互联网应用程序, 抵御DDoS攻击,阻止黑客入侵,并可助您实现零信任架构。
从任何设备访问1.1.1.1,即可开始使用我们的免费应用程序,让您的互联网更快更安全。
如需了解我们致力于构建更美好互联网的使命,请从此处开始。若您正在寻找新的职业方向,请查看我们的职位空缺。
本文文字及图片出自 Cloudflare 1.1.1.1 incident on July 14, 2025









> 对于许多用户而言,无法通过 1.1.1.1 解析器解析域名意味着基本上所有互联网服务均无法使用。
通常设备上会列出两个 DNS 服务器。那么第二个服务器是否也出现故障?如果没有,为什么没有切换到该服务器?
Cloudflare建议您将1.1.1.1和1.0.0.1配置为DNS服务器。
不幸的是,导致此次故障的配置错误禁用了Cloudflare对1.1.1.0/24和1.0.0.0/24前缀的BGP广告向其对等体发送。
更好的建议是将 Cloudflare 用作其中一个 DNS 服务器,而另一个则使用完全不同的公司。
只是好奇,你们是如何管理 Wi-Fi 门户并手动设置 DNS 服务的?我以前使用过 Cloudflare 和 Google 的服务,但每次使用公共 Wi-Fi 网络时,都要禁用和重新启用这些服务,这非常烦人。
DNS 只是一个查询服务。你可以过滤它或不过滤,但最终它只是一个“权威来源”。
你在 Wi-Fi 上想做什么?
许多Wi-Fi网络会将未加密的HTTP流量重定向到其 captive portal。为了使重定向生效,你的DNS必须设置为路由器提供的默认DNS,这样http://neverssl.com才能解析到Wi-Fi的“请接受我们的服务条款以连接网络”页面。
如果你未使用他们的DNS,则网络请求会被丢弃(因尚未获得授权)。你需要使用他们的DNS来学习如何访问他们的 captive host,以便他们能将你的MAC地址加入白名单。
没错,但理论上他们绝不会推荐使用竞争对手的服务
在 Android 系统中,进入设置 > 网络与互联网 > 私人 DNS,你只能在“私人 DNS 提供商主机名”中输入一个地址(据我所知)。
顺便说一句,我真的不明白为什么它不接受 IP 地址(如 1.1.1.1),而是必须输入一个地址(如 one.one.one.one)。从IP地址配置DNS服务器比通过DNS服务器解析地址更合理 :/
Android上的私有DNS指的是“DNS over HTTPS”,通常只接受主机名。
普通DNS通常可以在大多数Android版本的连接设置中,针对特定连接进行更改。
不,这不是 DNS over HTTPS,而是 DNS over TLS,两者不同。
Android 11 及更高版本同时支持 DoH 和 DoT。
这个选项在哪里?如何区分两者,对话框仅要求输入主机名
Cloudflare为1.1.1.1提供了有效的证书
> Android上的私有DNS指的是’DNS over HTTPS’
是的,抱歉我之前没有提到。
因此,如果你想在Android上使用DNS over HTTPS,无法提供备用方案。
> 因此,如果你想在 Android 上使用 DNS over HTTPS,就无法提供备用方案。
不正确。如果 (DoH) 主机有多个 A/AAAA 记录(多个 IP 地址),任何正常的 DoH 客户端都会尝试通过多个或所有这些 IP 地址重新发送请求。
Cloudflare是否提供任何主机名,该主机名同时解析到其他组织的解析器(该解析器必须为Cloudflare主机名配备TLS证书,否则DoH客户端无法连接)?
通常,对于普通DNS,主解析器和备用解析器来自同一提供商,但使用不同的IP地址。
是的,但你刚才提的是 DoH。我不确定这如何才能合理实现。
> 但你刚才提的是 DoH
DoH 主机可以解析到多个 IP 地址(甚至为不同客户端解析不同 IP 地址)?
另见 TFA
> DoH 主机可以解析为多个 IP 地址(甚至为不同客户端解析不同 IP 地址)?
是的,但不能来自不同组织。这是 GPs 的观点,
> 因此,如果您想在 Android 上使用 DNS over HTTPS,无法提供备用方案。
跨组织备用方案在许多客户端中无法通过 DoH 实现,但普通 DNS 可以。
> 值得注意的是,DoH(DNS over HTTPS)流量相对稳定,因为大多数 DoH 用户使用 cloudflare-dns.com 域名
是的,但这与切换到基础设施/运营上独立的备用服务器无关。
> 在许多客户端中,DoH无法实现跨组织级别的备用方案,但普通DNS可以实现。
这是客户端实现的缺陷,而非DoH本身固有的问题?
https://datatracker.ietf.org/doc/html/rfc8484#section-3
是的,但仅支持单个 DoH URL 的限制似乎是许多流行实现的标准。尽管协议理论上允许更优行为,但这并不能真正帮助使用这些实现的用户。
这是 DNS over TLS。Android 不支持除 Google DNS 之外的 DNS over HTTPS
自Android 11起支持。
仅限于部分DoH提供商。不允许输入自定义DoH URL,仅支持DoT主机名。
据我所知,是Google或Cloudflare?
Cloudflare 建议的配置是使用其备用服务器 1.0.0.1 作为二级 DNS,而该服务器也受到了此次事件的影响。
坦白说,目前导致 1.1.1.1 故障而 1.0.0.1 正常运行的故障模式并不多。在 CloudFlare 的规模下,单个 DNS 服务器出现故障几乎不可信,更可能是大规模系统故障。
但我理解为什么 Cloudflare 不能简单地说“使用 8.8.8.8 作为备用”。
至少有些机器/路由器没有主备配置,而是随机轮询切换。
这意味着你有一半时间连接到Cloudflare,另一半时间连接到Google,这可能并非你所期望的。
这取决于Cloudflare如何设置他们的系统。从这次和其他故障中,我认为很清楚他们将系统设置为单一故障域。但他们有可能将1.1.1.1和1.0.0.1设置为独立的故障域——独立的基础设施,至少有些网站运行一个但不运行另一个。
如果你认为自己可以对DNS指手画脚,那我建议你自己去运营服务。
注意根域名“.”多年来一直正常运行——这才是真正的工程设计,实际上比运行1.1.1.1复杂得多。1.1.1.1的问题在于使用了任播技术,而非DNS本身。
Cloudflare(以及Google等公司)坚持使用一个或多个“自定义”IP地址——这对我来说很不公平,但这就是事实,为了让它正常工作,他们必须使用任何播送。
真正的问题是修复任何播送,而不是DNS。
无论如何,选择两个或更多提供商并设置它们。
根服务器均使用任何播地址。
列出两个总比没有好,但效果不佳。若其中一个故障,系统无法追踪哪个仍在运行,因此常出现长时间卡顿和间歇性问题。
除非你通过本地缓存 DNS 代理(拥有多个上游服务器)进行复杂配置。
是的,我强烈建议使用离你最近的DNS服务器(对于那些ISP不会对DNS进行限制(如屏蔽等)的用户,通常能获得更快的响应时间),并使用多个不同提供商的DNS服务器。
如果你的设备不支持正确的故障转移,可以在路由器上使用本地DNS转发器或外部转发器。
在瑞士,我会使用Init7(不进行过滤的ISP)→ quad9(未过滤版本)→ eu dns0(未过滤版本)
你的生活有多忙碌,以至于我们需要关心最近的DNS?你是在像高频股票交易员一样浏览互联网吗?说真的,在日常生活中,除了发生这些事件时,有人会注意到解析域名时的延迟吗?
我明白理论上是这样,但现在我们有选择权,决定谁能看到所有请求,而ISP在列表中总是会输给其他服务商。
news.ycombinator.com 的 TTL 为 1,因此每次页面加载都会进行一次 DNS 请求(可能多次)。
如果你选择一个非常远的解析器,100 毫秒的页面加载延迟确实会迅速累积…
即使像 http://www.google.com 这样简单的域名,也从 5 个不同的 DNS 名称服务器提供服务。我见过高达 50 个的案例。这出人意料地快。尤其是在老旧浏览器上,它们一次只能打开 2 个连接。这种延迟累积的速度比你直觉上想象的要快。我曾经使用过本地解析器来调整TTL。但这带来的麻烦远大于收益。不过它确实能带来一定的速度提升。值得这样做吗?嗯,我觉得这样做挺有趣的。
你知道吗,我最近经历了一段以为我的MacBook坏了的时期。它运行得非常卡顿。浏览器上的所有操作都比平时慢得多。经过一周左右的折腾,我终于弄清楚了原因。新配置的电脑正在使用DHCP分配的DNS,而不是Google DNS。切换后,性能有了巨大的提升。
但这与从Google DNS切换到本地DNS的请求相反,因为延迟问题。你的ISP的DNS很差,这是一个笼统的说法,也是为什么像1.1.1.1或8.8.8.8这样的服务存在的原因。你没有更改DNS,因为你是根据最近的位置来选择的。
延迟不仅仅与距离有关。服务器响应时间也至关重要。在我看来,问题在于本地Wi-Fi接入点/路由器中的DNS转发器非常缓慢,尽管从我的笔记本电脑到该设备的ICMP延迟显然很低。
这当然没问题,但我的原意是,仅仅因为距离更近就切换到更近的 DNS 并不值得,尤其是当它通常是你的 ISP 服务器时。现在,你确认了仅仅切换到更近的 DNS 并不是解决办法,这进一步证实了不使用最近的 DNS 也是可以的。
我认为通常会将1.1.1.1与1.0.0.1配对,如果我理解正确的话,两者都曾出现过故障。
只需将1.1.1.1与9.9.9.9(Quad9)配对,这样在提供商层面也能实现故障容错。
我对Quad9有些失望,因为他们开始拒绝解析我的网站。它类似于wetransfer,但支持wget且没有AI扫描或插页广告。有用户上传了恶意软件,并可能将链接发送给恶意软件扫描器。但Quad9并未报告恶意上传或屏蔽特定URL¹,而是直接在DNS层面屏蔽了整个域名。而竞争对手wetransfer.com在9.9.9.9上解析正常。
我无法找到任何解决办法。恶意软件在线存在了数小时,但数周过去仍无法恢复我的域名声誉。有人在GitHub(该网站为开源项目)上建议,这可能是因为他们不了解该网站,就像大家都知道wetransfer和GitHub一样,因此不会因恶意用户内容而直接封锁整个域名。我找不到其他差异,但也没有责任方可咨询。Quad9网站上的误报报告工具仅重新加载页面而未采取任何行动
¹ 我知道DNS无法做到这一点,但如果有一种直接联系非常响应的行政管理员的方式(没有验证码或烦人的表单,只需发送邮件),我本不期望扫描器会直接封锁域名,至少在他们第一次收到反馈且问题内容已被迅速清除后不应如此。
你应该通过邮件联系他们,说明表单问题和你的域名情况。他们的邮箱地址在官网上列出。<https://quad9.net/support/contact/>
有时上游屏蔽列表提供商也容易直接联系,有时则不然。
我之前也曾遭遇过类似的滥用行为,涉及我的邮件服务器和曾经运营的一个社区论坛。当你试图按照规定操作却仍受制于冷酷无情的规则引擎时,确实令人沮丧。
你成功说服我放弃使用quad9。
在刚刚提交的工单中(见相关帖子),我询问了我的域名被列入了哪个黑名单。或许我们可以看看结果如何,也许他们能改进流程(例如移除该黑名单,或通知被封禁域名的滥用记录,以便域名所有者至少知道可以去哪里解决问题)
我在你的个人资料或网站/博客上没有看到联系方式,但我可以在这里发布结果
编辑:顺便说一句,我喜欢你博客的主题!
你的工单编号是多少?让我们看看能否帮你解决这个问题。
哦,没想到这会让这么多人看到,更别说你们了!
目前还没有工单号,因为我主要是试图在上游解决这个问题(即是谁将该域名添加到uBlock的默认阻止列表、Quad9以及其他地方),而今天当我专门检查您的网站时,在“误报?请联系我们”链接(当您查询被阻止的域名时)中,该链接只是跳转回自身,因此我也无法在那里提交工单。现在我再次查看该页面,考虑到之前评论中提到的建议,直接发送邮件给你们,我才意识到这可能应该通过通用联系表单提交,无需再通过域名状态页面。打开联系页面后,我看到“从阻止列表中移除”是一个可选项,所以我将使用该选项 🙂
我刚刚提交的工单编号是41905。并不是说我希望你们现在就给予特殊待遇,不过我原本也没指望上面那条帖子能被很多人看到,尽管我非常感激你们在这里主动联系我。这让我觉得你们可能真的对解决这类问题感兴趣,尤其是对小型网站运营商而言,这种完全封禁且毫无预警的做法,感觉上,嗯,可能不会有什么效果。如果流程能像往常一样正常运作,对我来说就足够了!感谢你鼓励我实际提交工单!
为什么不解决真正的核心问题:
> 我无法找到任何解决途径。[…] 似乎没有办法洗清我的名声。
从父评论中可以看出,解决途径是提交工单。但如果需要hn来处理,这并没有帮助。
Windows 11不允许使用此组合
你可以使用它,只需正确设置 DNS over HTTPS 模板,因为在混合使用提供商时,默认设置存在问题。
你需要的模板是:
1.1.1.1: https://cloudflare-dns.com/dns-query
9.9.9.9: https://dns.quad9.net/dns-query
8.8.8.8: https://dns.google/dns-query
有关如何设置模板的详细信息,请参阅 https://learn.microsoft.com/en-us/windows-server/networking/…。
太棒了!谢谢!
不客气。顺便说一下,我在这篇文章中看到过通过图形界面进行设置的描述:https://github.com/Curious4Tech/DNS-over-HTTPS-Set-Up
嗯?他们是否破坏了多年来存在于所有操作系统中的主/备DNS服务器设置?
DNS over HTTPS需要额外字段——URL模板——而Windows在某些情况下无法正确处理默认值。手动设置则可正常工作。
这与普通的 DNS 有什么关系?
没有关系,但 Windows 可以自动使用 DNS over HTTPS,如果它识别出服务器,这就是其他评论者提到的问题的根源。
具体如何?是否会拒绝不在同一子网的备用DNS服务器,或是类似情况?
它使用的是DNS over HTTPS,且在混合使用(部分)提供商时,无法正确默认URL模板。不过你可以手动设置,这样就能正常工作。
啊,这是关于DoH的,明白了!
这个“URL模板”似乎有些奇怪——Windows是否在通过DNS IP和模式创建URL,例如1.1.1.1 + “https://<ip>/foo”会生成https://1.1。1.1/foo?
如果真是这样,为什么不直接允许为每个服务器提供实际的URL呢?
它确实允许为每个服务器提供URL。问题只是其默认行为并不适用于所有提供商。我在这个帖子中还有另一条评论,告诉原评论者如何配置它。
太棒了,谢谢!
Quad9在转售流量日志,这意味着如果你连接到秘密主机(如工作用途),这些信息将被泄露
你能提供引用吗?你的陈述与Quad9在quad9.net上发布的官方信息完全相悖,而且更重要的是,它与Bill Woodcock已知的隐私倡导立场完全不符。
参见:https://quad9.net/privacy/policy/
它并未明确表示他们出售流量日志,但他们确实会将被阻止域名的遥测数据发送给阻止列表提供商,并向“经过严格筛选的少数安全研究人员”提供“带时间戳的 DNS 响应的稀疏统计样本”。这并非严格意义上的“出售流量日志”,但已相当接近。此外,从日常用语角度而言,即使谷歌仅披露汇总数据而非提供原始数据,人们仍常声称“谷歌出售你的数据”。
不同意“这与‘他们转售流量日志’的表述相当接近”以及“他们泄露所有查询的主机名”(“用于工作的秘密主机名也会被泄露”)的暗示。除非Quad9在欺骗用户,否则这两种说法实际上完全不实。
https://quad9.net/privacy/policy/#22-data-collected
>暗示他们泄露所有查询的主机名(“用于工作的秘密主机名也会被泄露”)。
关于与“经过严格筛选的少数安全研究人员”共享数据的部分,并不排除他们泄露域名的可能性。例如,如果安全研究人员导出一个“SELECT COUNT(*) GROUP BY hostname”查询,这可以被视为“摘要形式”,并且会包含任何秘密主机名。
>https://quad9.net/privacy/policy/#22-data-collected
如果你试图暗示他们不可能泄露主机名,因为他们不收集主机名,那么这一说法与后续章节的内容直接矛盾,因为这些章节明确提到他们会按主机名分组共享指标。显然,他们需要收集主机名才能提供此类信息。
我暗示的是,我确信他们并未存储(因此泄露)每个查询的主机名统计数据。正如你自己所承认的,他们明确表示,他们对第三方提供的“一组恶意域名”进行统计分析,作为其阻断计划的一部分。此外,他们定期发布“前500个域名”列表。如果你想让“秘密域名,比如用于工作”(即每个被查询的唯一域名)符合这里的情况,那你就是在强行套用。
>我暗示的是,我确信他们并未存储(从而泄露)每个被查询的主机名的统计数据。正如你自己承认的,他们明确表示,他们会对第三方提供的恶意域名集进行统计,作为其屏蔽计划的一部分。
没错,但隐私政策还提到有一个针对“少数经过严格审核的安全研究人员”的独立计划,他们可以以“摘要形式”获取数据,这可能以我之前评论中描述的方式泄露域名。也许他们有一个优秀的IRB(或类似机构)可以防止这种情况发生,但隐私政策中并未提及这一点。因此,泄露秘密域名完全有可能发生,无需“硬塞”任何东西。
我们完全致力于保护最终用户的隐私。因此,Quad9 故意设计为无法捕获最终用户的个人身份信息(PII)。我们的隐私政策明确规定,查询从未与个人或 IP 地址相关联,且此政策已嵌入我们系统的技术(不)能力中。
这涉及主机名本身,例如:git.nationalpolice.se,但我理解若想保持服务免费使用,选择余地有限,因此这可以理解。
这真的会让大多数人担心吗?如今试图保密主机名本就是一场徒劳的斗争。
你应该使用受信任的 TLS 证书来托管 Git。这意味着主机名最终会出现在证书透明度日志中,而这些日志比 DNS 查询更容易被抓取。
这是真的吗?他们声称不保留任何日志。你有来源吗?
他们没有这样声称。不到一周前,HN讨论了他们的顶级解析域名报告。这样的报告暗示他们有日志。
来自他们的主页:
> Quad9如何保护您的隐私?
> 当您的设备正常使用Quad9时,任何包含您IP地址的数据都不会被记录在任何Quad9系统中。
当然他们有一些类型的日志。汇总解析域名而不记录客户端IP地址,这与“Quad9在转售流量日志”的暗示并不一致。
我们讨论的不是IP地址,而是他们的日志是否会泄露您的秘密域名。
这样说更清楚了,我明白您的意思了。不过,大多数人不会这样解读原评论。我从未想过自己可能会生成一些存在可能被视为敏感的主机名。从一开始这似乎就是个糟糕的主意,因为我确信还有其他途径可能导致这些“秘密”域名泄露。或许可以将秘密虚拟机命名为vm1、vm2等,而不是使用<你的根密码>。不过,这并非我的专业领域,也不是绝大多数希望获得比ISP提供的更多隐私保护的互联网用户关心的问题。
不过我很好奇,你有没有更好的替代DNS建议?
我使用Google DNS,因为我觉得它符合我对隐私威胁的个人理论。在各种公共DNS解析服务中,我认为它们在防范内部监视和外部黑客入侵系统方面拥有最佳的技术防御措施,而且我对它们的永久日志并不担心。我也不在意Quad9的日志,除非它似乎与他们宣传的隐私理念不一致。我在配置中将Quad9作为最后的解析器。我怀疑实际查询很少会发送到那里。
抱歉……什么是公开可解析的秘密主机名?
这个想法让我觉得不负责任且误导。
它可能是某个难以猜测的子域名。你通常无法通过DNS枚举所有子域名,而且如果你使用通配符TLS证书(或自签名/无证书),它也不会泄露到CT日志中。秘密主机名。
示例:github.internal.companyname.com 或 jira.corp.org 或 jenkins-ci.internal-finance.acme-corp.com 或 grafana.monitoring.initech.io 或 confluence.prod.internal.companyx.com 等
这些地址,如果你不知道主机名,就无法访问后端服务。但如果你知道,就可以开始利用它,无论是由于缺乏认证,还是试图利用软件本身
没错,基本上是这样。在理想情况下,你可能会将其与另一个服务配对,但通常会使用官方备用 IP,因为它不应该同时出现故障。
我宁愿通过根服务器进行缓慢的解析,也不愿从一个递归解析器切换到另一个。
8.8.8.8 + 1.1.1.1 稳定且相对安全
这就是我的做法。我在路由器中同时设置了这两个服务,因此它尝试的完整列表是 1.1.1.1、1.0.0.1、8.8.8.8 和 8.8.4.4
Windows 11 不允许使用此组合
如果你在接口上设置它,它就可以使用
或者如果你能的话,运行你自己的。
1.1.1.1 也是他们所称的解析服务整体,影响部分(似乎)指出 1.0.0.0/24 和 1.1.1.0/24 均受影响(及其他范围)。
我的Mikrotik路由器(以及据我所知所有同类设备)不支持配置多个DoH地址。
并非所有用户都配置了两个DNS服务器?
强烈建议配置两个或更多DNS服务器,以防其中一个不可用。
未配置至少两个DNS服务器可视为“用户错误”。许多系统要求输入主服务器和备用服务器才能保存配置。
有趣的是,像Cloudflare这样的服务会说“哦,是的,只需将1.0.0.1设为备用服务器”,但实际上这应是完全不同的服务。
大多数计算机的默认设置似乎是:使用(Wi-Fi)路由器。我猜电信公司喜欢这样,因为这可以减少DNS请求的数量。所以我不会把它视为用户错误。
好的。但如果他们已经手动配置了主DNS,就没有理由或借口不这样做。
没错。我使用Cloudflare和Quad9
我工作过的每个地方都是3。
有趣的是,这次大约20分钟的故障可能导致1.1.1.1的使用量减少了20%。
不明白Cloudflare为何总是遇到这类问题,这并非第一次(也不会是最后一次)出现这类“简单”、“过时”、“遗留”问题。
8.8.8.8+8.8.4.4在近十年间从未出现过全球范围内的停机(1)。
1:确实存在局部问题,但这主要是互联网本身的故障,即使谷歌自身在不同服务中遭遇严重停机时,它们仍保持运行。
DNS 的重要性不仅在于可用性(当然,这非常重要)。速度和隐私同样重要。
欧洲用户可能更倾向于选择 https://european-alternatives.eu/category/public-dns 中列出的替代方案,而非受《云法案》(CLOUD Act)约束的美国企业。
我认为直接部署Unbound会更简单。服务器来来去去,彻底摆脱对DNS服务器的依赖比担心谁在运营这些服务器以及它们能可用多久更好。
我确信自己95%是在数据中心运行Unbound,并且本地部署了Pi-hole。我的电脑首先连接到Pi-hole,如果Pi-hole不可用,则连接到我的数据中心;Pi-hole会连接到数据中心和其中一个过滤DNS提供商(不记得具体是哪一个)以及GTEi的旧服务器,该服务器至今仍正常工作且从未让我失望。不,不是那个,是另一个。
我使用Musknet,因此无法在不购买新路由器的情况下修改路由器上的DNS提供商设置,因此手机不会自动加入此计划,虚拟机等设备也不在其中。
拥有第二个可信赖的路由器会消耗额外能源,但或许值得。我的路由器曾多次在更新后悄然禁用Pi-hole。
在盒子里备有一个完全配置好的Pi-hole也颇有帮助。另一次在停电后,我的Pi-hole拒绝启动。
我完全同意。我是《如何在<hypervisor>中运行IPCop/Monowall》系列文章的作者,发表于BroadbandReports。因此,当我听说可以通过第三方路由器在Starlink上获得真实、可公开路由的IPv6地址时,我立即在Proxmox本地环境中搭建了一个。所有“路由器发行版”要么无法正常工作,要么根本不支持IPv6,而且我尝试过的所有版本都没有任何IPv6设置选项。
于是,我去了百思买买了3台路由器,并分别设置了1周。结果发现,如果你使用支持IPv6的第三方路由器,确实可以获得公共可路由的IPv6地址。
我偶尔还会看到有人在这里提到opnsense和pfsense,我不禁怀疑自己是不是用错了——可能是过时的——ISO镜像?我也尝试过用FreeBSD和Debian来做,但始终没能搞清楚,这让我有点沮丧。我以后会再试一次。
无论是否是欧洲人,只要认为隐私有价值,都应该选择任何其他服务,而不是Cloudflare和Google。
HN用户可能更倾向于自行运行。这是一种低维护的服务。它不像运行邮件服务器那样复杂。
我认为这可能高估了HN读者的整体技术能力。当然,设置Unbound作为通用DNS转发器并不需要什么高深技术,但这并非大多数人需要的即点即用型服务。它应该与直接将系统解析器更改为dns0、Quad9等进行比较。
自行运行并作为唯一用户使用,与使用DNS服务器本质上是相同的(你需要为任何给定域名获取名称服务器,而这需要联系DNS服务器)。
这里的一个问题是,你可以被轻松追踪。
> 不确定Cloudflare为何在处理此类问题时仍面临困难
Cloudflare在事件响应方面有合理的文化,但它并不鼓励主动预防。
你确定他们不明白如何解决一个由复杂性和规模特征定义的工程问题,而这个问题仅有0.001%的网络工程师遇到过?
关于20%的客户端/解析器会在服务器连续多次未响应查询时将其标记为临时不可用。这样用户就无需在接下来的500次查询中连续等待500次超时延迟。
从长期图表来看,流量已恢复正常 https://imgur.com/a/8a1H8eL
那么您将使用谷歌DNS,但这对于许多人来说是不理想的。
是的,我诚实地切换回了8.8.8.8和8.8.4.4谷歌DNS。100%稳定,无过滤,在欧盟地区速度快。
我对影响检测的延迟感到惊讶:他们的内部健康服务花了超过五分钟才注意到(或至少发出警报)其主要协议的流量突然降至预期值的10%左右并保持该水平。如果我从未参与过此类规模的监控,我会认为如此极端的异常情况会在不到一分钟内触发警报。我很好奇这种情况是如何发生的,以及在该领域专业人士看来,这是否合理或令人惊讶。
检测速度与误报率之间始终存在矛盾。
传统监控系统如Nagios和Icinga设有设置,仅在检查连续失败三次时触发事件/警报,因为虚假失败检查相当常见。
如果向运维人员发送大量自行修复的监控检查警报,会无端增加他们的压力并导致警报疲劳,因为他们的第一反应往往是“先等一等,看看是否能自行修复”。
我从未运营过像CF的DNS服务那样高暴露度的服务,但看到检测耗时8分钟才可靠地触发,我并不感到意外。
我在一家拥有约20万月活跃用户的B2B公司负责单点登录(SSO)架构。我们监控中的一个盲点是,当由于我们自身问题导致客户的身份提供商出现错误时,服务无法使用且没有错误日志触发警报。我们曾尝试基于预期与实际流量差异设置警报,但最终认为这会因你提到的原因引发更多问题。
在Cloudflare的1.1.1.1规模下,我认为可以采用相对简单的方案,例如跟踪10分钟和10秒的滚动平均值(我知道这听起来比实际操作简单得多),如果两者差异超过50%,则触发警报。(具体数值可能需要调整,例如20秒或80%,但核心思路是这样。)
如果规模远小于1.1.1.1本身,报警时间超过一分钟可能并不令人意外,但1.1.1.1处理的是海量且相对稳定的流量。
我参与的项目规模与1.1.1.1相当,如果我们采用这种架构,值班人员将无法休息(实际上这种情况几乎已经存在,但无奈)。说“只要实现X监控就能发现问题”很容易,但这涉及实际的人力成本,你必须极其警惕地删除监控,否则会被无休止的误报页面淹没。我认为对于这种规模的服务,5分钟的延迟并不算过分。
这似乎是个基本问题:整个服务基本上都瘫痪了,却花了6分钟以上才发现?我越来越不明白这是怎么一回事。这并不是什么高级监控工具,这或许是我最期待首先实施的监控工具(基于没有相关经验的判断)。
> 基于没有相关经验
我不想把这变成一场权威论证,但——监控系统在那个规模下有很多权衡。其中之一是,聚合在规模上需要时间,而且随着足够多的指标和数据涌入,你的方差会到处都是。分布式系统在这个规模下的核心事实是,堆栈的某个地方总会出现故障——平均法则要求如此,因此如果你在系统任何部分出现故障时都触发全局警报,那么警报将24/7不断响起。实际上,在我们讨论的这种规模和复杂度的机器上,能在5分钟内检测到实际故障的发生,绝对是了不起的成就。
我敢肯定,Cloudflare 的某位工程师正在评估类似方案,并尝试用历史数据测试过去会产生多少误报(如果有的话)。
问题是,这可能仍需一定的工程投入,而大多数组织通常只有在监控被证明不够优化后才会改进。
这绝不是1.1.1.1的第一次故障。这可能也是你首先想到的外部监控行为。这就是为什么我感到惊讶——实际上,我越想越惊讶;超过五分钟的延迟才发现如此根本性的故障,这实在太久了。
你们的外部监控是否正常工作?有多少次检查失败,失败的顺序是怎样的?涉及多少个不同地区或系统?是暂时的故障吗?你们会重试多少次,重试的频率是多少?你们是推送成功或失败的指标,还是拉取?如果指标无法返回,你们会等待多长时间才认为是问题?您还运行哪些其他检查,这些检查需要多长时间?此类检查的可接受延迟是多少?您愿意接受多少次误报,以及以何种频率?
我希望确保我们避免“我们应该始终做确切的特定事情来防止这个确切的特定问题”式的思维。
这是过去在网络运营中心(NOC)巨型墙上会展示的图表之一——有人会抬头看到数据下降并说“这不对劲”,然后开始紧急处理。
这就是我想象的情景。难道不是这样吗? everyone 都在家工作,大图表在电视上显示,但家里有人换了频道?
服务在影响开始时几乎肯定没有完全崩溃,尤其是如果这是全球部署的开始。影响需要时间才能变得可测量。
我并不感到惊讶。
假设你有一个指标聚合服务,而该服务崩溃了。
这会导致什么结果?指标会延迟,直到你的编排系统在其他地方重新部署该服务,这看起来像是指标的100%下降。
大多数编排系统在这种情况下需要几秒钟才能重新部署,假设这是节点的一时故障(如网络故障)。
所以,如果你在仅一分钟后触发警报,最终会导致人们在凌晨2点被无故叫醒。
如果人们在凌晨2点被叫醒,而问题在5分钟内自动解决,会发生什么?人们会辞职,或者最终将警报调整为5分钟。
我知道你通常可以区分无数据和真实下降,但“如果你不断打扰人们,人们会辞职”这一点我认为是关键。如果人们因过紧的警报不断被打扰,警报可以且应该放宽……这就是最终调整为5分钟的原因。
你假设的情景中真正的问题是,单个不良指标实例可能导致整个系统崩溃。你可以部署多个地理分布的指标聚合服务,通过RAFT/PAXOS共识机制建立“权威状态”。只要大多数指标聚合实例正常运行,系统就能继续工作。
当构建类似1.1.1.1的系统时,5分钟的告警汇总是不被接受的,因为这会掩盖持续时间在0到5分钟之间的合法停机时间。
你需要设计不依赖于编排来修复短暂错误的系统。
披露:我所在的公司拥有超过5亿用户,我参与了核心SRE团队的工作。
对于小型公司来说,这并没有错。但有人认为,像Cloudflare这样的大型关键系统公司/服务提供商应该能够承担起自己的全天候团队,包括夜班。
请不要这样做。这没有意义,不会有帮助,不会改善任何事情,只是浪费金钱、时间、电力和人力。
现在不哭了:我看到多家大型公司取消了网络运营中心(NOC),转而采用多个专注团队轮班制。与让12人分组轮班24/7进行基本分析和初步处理再通知他人相比,现在只需在3-5分钟内通过精准具体的警报通知相关人员。
事件解决时间大幅缩短(2-10倍,具体取决于公司),员工无需通宵值班并大部分时间睡觉,也不会因采取诸如服务重启等愚蠢措施而拖慢事件解决进程。
我不喜欢某些平台雇佣1500人来完成本可由50-100人完成的工作,但在事件响应方面,如果已经拥有职责分离的团队,那么NOC就是“过时”的。
24/7值班在任何大型网络中都是强制性的,而Cloudflare就是这样一个网络。你与其他网络的合同关系将要求这一点。
我并不认为HN上的SWE群体,特别是那些出现在每个关于AI“代理”的帖子中的群体,真的知道如何运营一个全球网络或什么是NOC。我知道在这里说这些可能会招致Vint Cerf或类似人物在回复中现身,但现在情况已经严重失控。除了那些对AI公司阿谀奉承的帖子外,每个HN帖子都演变成对人们一无所知的主题进行沙发评论。这种情况比ChatGPT出现前要糟糕得多。
哈哈,说得好
(曾在大型全球平台担任SRE)
过去几年我基本上对这类回应置之不理,尽量不与之互动。这种缺乏专业知识的“如果是我,我根本不会那样做”的评论风格,在我看来,早在AI出现之前就在这个网站上普遍存在。
> 每个不涉及对AI公司吹捧的HN帖子,都演变成红迪用户对他们一无所知的主题进行 armchair 分析。
我花了很多时间才意识到这一点^。我曾在两家大型公司与两个NOC团队合作过,我知道这些团队在那些公司仍然存在。不过我不是软件工程师。而且我也不确定这两家公司是否能真正被称为“全球性”公司,除非在最宽泛的意义上——比如其中一家公司的主要子公司名称中含有“美国”字样。
^ 我甚至经常使用“评论中人们在纠正彼此关于<x>的错误”这种表述,因此我潜意识里就知道HN只是互联网评论的一个子集。问题在于这个网站看起来是经过审核的,而选择在这里评论的人群似乎在理解和支持主张方面都高于平均水平。“纠正”这个标签来自n-gate,我上次查看时,它自20年代初就再也没有更新过。
问题是,哪种方式更好:24/7轮班工作(确保有人随时在岗响应,但睡眠时间表会定期被中断)还是24/7待命(通过监控和警报系统导致随机间歇性睡眠中断,有时是误报)?
甚至不是夜班,只是在世界另一端正常工作时间。
随着公司规模的扩大,会出现一些重大转变。
步骤1:最初由创始人承担27x7x365的待命工作,或前10至20名员工在周末和晚上“携带传呼机”,整个公司都参与无薪轮班待命。
步骤2:你偷走所有内衣。
步骤3:你拥有分布在全球各地的“跟随太阳”办公时间支持团队,足以覆盖假期、意外生病或辞职的情况。
我对你的步骤2感到困惑。
我就像,拜托!这是《南方公园》的梗吗?难道这里没人明白吗???
<google google google>
“首播日期:1998年12月16日”
哦,对啊。你们一半人还没出生呢……现在我感觉自己好老啊。
我认为,如果报警触发时间是解决大多数问题所需时间的5-10%,这是合理的。
与其给我点赞,我更想知道为什么这不合理?
这没什么大不了的。你可以分两步走:为什么不在前5分钟内先检查聚合服务是否崩溃,再触发警报?能有多少种误报情况?你只需要消除最常见的那些,最终就会减少它们的数量。
在触发快速警报之前,先检查节点是否正常运行,服务是否正常运行等。
> 可能有多少种误报类型?
在云flare的规模下运行?很多。
* 流量似乎下降了90%,但我们只收到了来自全球那些因管道错误而处于睡眠状态的地区的指标
* 流量似乎下降了90%,但有人设置了防火墙规则导致指标丢失
* 流量似乎下降了 90%,但实际上计数器已滚动,而 Prometheus 处理不当
* 流量似乎下降了 90%,但新版本的发布时间导致轮询显示异常数据
* 流量似乎下降了 90%,但实际上指标报告出现峰值且管道存在延迟
* 流量似乎下降了 90%,但实际上负责中转链路的团队忘记为 SNMP 设置正确的访问控制列表(ACL),因此我们无法收集 90% 流量的指标
* 我不断收到流量下降 90% 的警报…… 成千上万次,但实际上只是因为这个很少使用的警报存在一些数据腐烂问题,它使用的是按系统而非聚合的指标。
* 流量实际上下降了90%,因为存在互联网路由问题(这不是DNS团队的问题)
* 某一数据中心的流量实际上下降了90%,因为某处光纤断裂
* 流量实际上下降了90%,因为正常使用模式下谷值流量仅为峰值流量的10%
* 流量较10秒前下降了90%,但10秒前曾出现异常流量峰值。
随后,由于监控全球庞大数据中心网络的指标系统规模庞大且分布式,还会引发各种额外问题。
在1分钟内触发警报只会成为对警报基础设施的压力测试。你的警报基础设施能否在1分钟内实时获取指标并进行计算?
记住他们没有为这项服务提供SLA。
那又怎样?
他们对该服务的可靠性有着相当大的利益关联。
写得不错。
> 值得注意的是,DoH(DNS-over-HTTPS)流量相对稳定,因为大多数DoH用户通过手动配置或浏览器设置使用域名cloudflare-dns.com访问公共DNS解析器,而非直接使用IP地址。
有趣,我昨天也遇到了这个问题。我的路由器(据说)启用了Cloudflare DoH,但无法解析任何地址。将DNS服务器改为8.8.8.8后问题解决。
DoH是如何工作的?你需要先知道cloudflare-dns.com的IP地址。也许你的路由器使用1.1.1.1来实现这一点。
是的,你的操作系统首先需要解析cloudflare-dns.com。这次初始解析很可能通过网络的默认DNS以明文形式进行。只有在解析成功后,你的系统才会向该地址发送DoH请求。
需要注意的是,如果之前的缓存已过期,每次DNS请求都会引入一次查询开销。出于这个原因,我一直使用https://1.1.1.1/dns-query作为替代方案。
理论上,这应消除该开销。您的操作系统可通过 DoH 服务器提供的 CA 证书中的“主题替代名称”(SAN)字段验证 DNS 响应的 IP 地址:https://g.co/gemini/share/40af4514cb6e
我们是否需要使用域名?我一直只使用 IP 地址。
您需要域名才能使 HTTPS 中的“s”生效
那是不正确的。
LetEncrypt目前正在测试基于IP地址的HTTPS/TLS证书:
https://letsencrypt.org/2025/07/01/issuing-our-first-ip-addr…
他们表示:
“从原则上讲,没有理由不能为 IP 地址而非域名签发证书,事实上,证书的技术和政策标准一直允许这样做,少数证书颁发机构也曾小规模提供此类服务。”
没错,大约两周前此事曾引起一些轰动。那么从原则上讲,二十年前就没有理由不这样做吗?那时候有这样的服务就好了。我从未听说过有任何证书颁发机构提供此类服务。
> 我从未听说过有任何证书颁发机构提供此类服务。
DigiCert 提供。1.1.1.1 和 9.9.9.9 的有效证书就是从那里获取的
大多数 CA 都提供此类证书,唯一要求是证书至少为 OV(而非 DV)级别,且主体组织需证明其拥有该 IP 地址。
在 HTTPS 初期,人们需要通过查看锁形图标来判断网站是否安全。毕竟,诈骗分子不会花时间和金钱去获取证书!
因此,证书通常与身份绑定,而 IP 地址本身并不具备身份属性,因此提供此类服务的提供商寥寥无几。
IP 地址与域名一样,都是一种身份标识。
过去IP证书未被广泛采用的主要原因有两个:
– 在SAN扩展出现之前,证书中仅包含一个CN(证书名称),且每个证书只能有一个CN。将唯一的CN设置为单个IP地址通常是一种浪费(或需要花费更多资金购买更多证书并维护相关基础设施)。一个域名可以解析到多个IP地址,且这些IP地址随时间可能发生变化;用户通常希望访问如microsoft.com等域名,而非当前解析到的具体IP地址。如今SAN已存在一段时间,因此这一限制已不复存在。
– 域名验证(提供随机DNS记录)涉及在您的域名下创建普通正向解析记录。通过DNS验证IP地址需要在in-addr.arpa域的反向查找中添加记录,其难度从烦人(您为拥有自有/8、/16或/24网段的大型组织工作)到不可能(您从低成本ISP租赁少量无关联的IP地址)。如今,借助HTTP验证(在80端口提供此随机页面),IP地址验证变得更加可行,但此前这是一种不必要且不受支持的验证方式。
不,那是不正确的。https://1.1.1.1/dns-query是我几个月来一直在使用的完全有效的DoH解析器地址。
您的操作系统可以通过 DoH 服务器提供的 CA 证书中的“主题替代名称”(SAN)字段验证 DNS 响应的 IP 地址:https://g.co/gemini/share/40af4514cb6e
那么 IP 地址的证书呢?
如果路由被劫持怎么办?IP 地址没有 HSTS。
假设路由劫持者没有证书的有效私钥,因此无法通过验证
反向DNS解析怎么办?
我也不明白这一部分,也许它是通过你的 ISP 的 DNS 服务器进行初始化的?
基本上就是这样。你设置一个初始化 DNS 服务器(可以是你的 ISP 或任何其他服务器),然后它解析 DoH 服务器的 IP 地址,之后可以用于所有未来的请求。
即使你已经解析了它,TTL也只有5分钟
[删除]
这听起来像是AI,完全没有回答问题。
DOH服务器的IP地址是如何获取的?
Firefox接受一个启动IP地址,或使用系统解析器:
> network.trr.bootstrapAddress
> (默认:无)通过将此字段设置为“network.trr.uri”中使用的宿主名IP地址,您可以绕过使用系统原生解析器。使用此方法获取 Cloudflare 服务器的 IP 地址:https://dns.google/query?name=mozilla.cloudflare-dns.com
> _从 Firefox 74 开始,在模式 3 中设置引导地址不再必要。Firefox 将尝试使用常规 DNS 获取受信任解析器的 IP 地址。然而,如果解析器域名的 DNS 解析失败,则再次需要设置引导地址。
来源:https://wiki.mozilla.org/Trusted_Recursive_Resolver
有趣。今天我在配置一个新域名时,大约20分钟内只能通过一台笔记本电脑上的Firefox访问该域名。Google的DNS工具显示其处于活动状态。通过SSH连接到一台能解析该域名的亚马逊服务器。我的本地网络对此一无所知。清空缓存后仍无改善。结果发现,那台FF浏览器被设置为使用Cloudflare的DoH。
我不同意。这里真正的根本原因被专业术语所掩盖,即使像我这样的资深管理员也需要费力解析。
这是企业新话。 “遗留”并非一个清晰的术语,它被用来抽象化和模糊化。
> 遗留组件未采用渐进式分阶段部署方法。Cloudflare将淘汰这些系统,以便通过现代渐进式和健康管理部署流程,以分阶段方式提供早期预警并相应回滚。
我明白这是什么意思,但完全没有必要用这种难以理解的官僚语言来表达。
我不同意,目标受众也包括非技术人员,而核心要点对所有人都清晰:他们只是将此配置从0%直接部署到100%生产环境,没有功能门控或回滚机制。而且他们对配置进行了修改,但这些修改数周后才部署,直到其他更改被实施,这显然也涉嫌流程错误。
我不会评论这对他们这样规模和成熟度的公司是否可接受,但这绝不是用企业行话来掩饰的。
我认为他们本可以更详细地说明将采取的后续措施以防止此类问题再次发生,我认为分阶段部署并非唯一解决方案,它只是一个安全网。
如果你继续阅读,很明显他们配置了一个服务时出现了错误,并将生产流量路由到了该服务而非正确的服务。而用于实现这一功能的系统建于2018年,已被视为遗留系统(可能是因为该系统容易部署错误配置)。基于此,我不会说这份总结是“难以理解的官僚术语”,无论那指的是什么。
我同意这不是“难以理解的官僚主义语言”
它是经过精心撰写的,以便我的老板的老板认为他理解它,并且我们不可能有这个问题,因为我们显然没有“遗留组件”,因为我们是“现代和进步的”。
在我看来,它更接近“故意误导的官僚主义语言”。
乔·史莫将错误的配置文件提交到了生产环境。这是一个无心的错误。莎莉在30秒内发现了它。我们在2分钟内恢复了服务。我们让乔去玛格丽塔酒吧放松一下,修复他受损的神经。这孩子值得加薪。等等。
是的,帖子中后来分享的流量图表显示,所谓的“时间线”标注的故障开始/结束时间完全不准确。
或者他们对“影响”的定义与我不同
我的(Unifi)路由器设置为自动DoH,我认为这意味着它使用了Cloudflare和Google。没有注意到任何中断,所以要么Cloudflare的DoH继续工作,要么在它下线时使用了Google的。
查看Jallmann的回复https://news.ycombinator.com/item?id=44578490#44578917
简而言之:DoH正常工作
据我所知,Jallmann只留了一条评论,而且是顶级评论。我不确定你所说的“Jallmann的回复”指的是什么。
这篇文章写得很好,除了开头分享的完全错误的时间线
我认为你需要澄清这样的陈述。
现在是时候提一下dnsmasq允许你设置多个DNS服务器,并且可以进行竞速。第一个响应的服务器获胜。你永远不会注意到其中一个服务不可用:
此外,只要您未设置 strict-order,dnsmasq 会自动使用 all-servers 进行重试。
如果您使用的是 systemd-resolved,它会按指定顺序依次重试所有服务器,因此需要交错配置上游服务器。
使用上述示例中的服务器,并假设 IPv4 + IPv6:
在 systemd-resolved 上切换到备用服务器会更快且更成功,而不是将所有 Cloudflare IP 地址一起指定,然后再指定所有 Google IP 地址等。
还需要注意的是,Quad9 在此 IP 上默认启用过滤功能,而其他两个则没有,因此您可能会遇到解析行为的间歇性差异。如果这是个问题,请不要混合使用过滤和未过滤的解析器。如果你关心 DNSSEC 验证,绝对不应混合使用 DNSSEC 验证和不验证的解析器(上述所有解析器均支持 DNSSEC 验证)。
哇,好建议
我正在处理因此次故障引发的事件。我最终通过 systemd-resolved 添加了 Google DNS 解析器,但没想到要交替使用它们!
从理论上讲这听起来不错,但有没有更私密的配置方案,避免将DNS解析请求发送至Cloudflare、Google等云服务商?即避免被大型科技公司追踪,且不希望使用DOH。
使用dnsmasq并配置一份小型可信DNS提供商列表似乎完美,只要这样做不被视为对多个DNS提供商进行“垃圾请求”的违规行为?
但如何找到一份专注于隐私的可信DNS解析器列表?我从网上随机尝试的几个似乎不太稳定。
没有好的私有DNS配置,但如果你不信任大型缓存递归解析器,我建议在家自行运行一个。Unbound易于设置,你可能不会注意到速度差异。
我更信任我的 ISP 而不是 Cloudflare 和 Google
为什么?有些 DNS 服务器会注入广告、阻断服务、降低视频质量或其他不当行为。
也许他们的 ISP 不会这样做。地球上有很多 ISP。
我审查了各种DoH服务器的隐私政策和性能,并认为Cloudflare和Google都提供了尊重隐私的政策。
我相信他们遵循其公布的政策,并拥有合理的安全团队。他们也是流行的服务,这减轻了其他类型的DNS跟踪的可能性。
https://developers.google.com/speed/public-dns/privacy https://developers.cloudflare.com/1.1.1.1/privacy/public-dns…
NextDNS。免费层级非常慷慨,付费层级也非常实惠。作为用户已有数年,从未遇到过服务中断。
同样,他们让跨设备使用变得轻松,每个设备都有定制配置。
这个
https://www.dns0.eu/ 是一个选项
我使用OpenNIC时没有遇到任何问题:https://opennic.org/
> OpenNIC(也称为OpenNIC项目)是一个由用户拥有和控制的顶级网络信息中心,提供传统顶级域名(TLD)注册机构(如ICANN)的非国家替代方案。
使用 DNSCrypt 配合匿名 DNS 可能是另一种选择:https://github.com/DNSCrypt/dnscrypt-proxy/wiki/Anonymized-D…
Quad9和NextDNS常被提及。
你可以运行unbound或其他类似工具,自行进行递归解析。
dnsforge.de是个值得考虑的选项。
我认为这些选项不可互换。它们有不同的优先级和政策。如果一定要选,我会选择一个,并将 ISP 的默认设置作为备用。
我的 ISP(美国最大的 ISP 之一)喜欢劫持 DNS 响应(尤其是 NXDOMAIN),并提供垃圾内容。谢谢,不要。这也是为什么我必须使用加密来与公共 DNS 服务器通信,否则它们仍然会劫持。
我的ISP已经被发现出售客户的个人身份信息。我对他们的信任程度甚至低于那些公司。
我的ISP在开始返回包括无效网站在内的任何搜索结果后,就被踢出了服务。基本上是为了引导你使用他们的搜索引擎。
原则上同意,但有人看到这些DNS服务之间有实际差异吗?与使用ISP默认设置作为备用方案相比,并行使用这些服务会有什么更详细的缺点?
其中一些服务非常注重隐私保护,会阻止将你的位置发送给原始DNS服务器,这会导致任何播送无法工作,从而导致访问网站的速度变慢。
我认为如果使用systemd-resolved,它会做类似的事情。默认支持DoT和DNSSEC。
如果你想完全避免使用集中式DNS,如果你运行一个Tor守护进程,它有一个选项可以将DNS解析器暴露给你的网络。如果你需要,可以有多个解析器。
即使没有“all-servers”选项,DNSMasq也会频繁切换服务器(每20秒一次,除非手动更改),并在重试时同样如此。突发故障最多只会影响您几秒钟,甚至可能完全不影响。
dnsdist 作为一个安全的本地解析器,设置起来非常简单,它会将所有查询转发到 DoH(并检查 SSL),并且每秒检查一次连接状态
我需要有一天写一篇文章
请务必写一篇。我很好奇一个默认安全的自托管解析器会是什么样子。
供参考,以下是最基本的(但完全可用的)配置,用于将 Unbound 作为仅支持 DoT 的转发器运行:
看来AdGuard也支持相同功能,感谢提及dnsmasq支持!我在配置时疏忽了这一点。
对用户来说可能很棒。但对于尝试复现问题来说很糟糕。我个人更倾向于采用更确定性的方法。
大约 1 小时的停机时间相当于一个月中的 0.13% 或一年中的 0.0114%。
很想看看 Cloudflare 内部为该服务设定的服务级别目标(SLO)。
我找到了 https://www.cloudflare.com/r2-service-level-agreement/,但这似乎仅适用于付费服务,因此此次停机将使7月进入“<99.9%但≥99.0%”的区间,若您已付费,当月可获得10%的退款。
从“维护可靠性声誉”的角度来看,年度可用性可能达到99.9%或更高。
这些百分比的关键在于是按月还是按年计算。按年计算的99.9%允许的停机时间远长于按月计算的99.9%。
有趣的是,事件发生后,流量并未完全恢复到正常水平。
我最近开始在OpenWrt上使用“luci-app-https-dns-proxy”包,该包预配置为同时使用Cloudflare和Google DNS,由于DoH基本未受影响,我并未注意到服务中断。(不过如果DoH受到影响,它应该会自动切换到Google DNS。)
> 值得注意的是,事件发生后流量并未完全恢复到正常水平。
根据我的观察,我发现他们的DNS在状态页面显示故障前就已经出现问题,于是将上游DNS切换到了Google。目前还没来得及切换回原设置。
有什么理由要从Google DNS切换回来?
在多次尝试后,我最终选择继续使用Google,因为Cloudflare在涉及CDN时总是返回非常糟糕的IP地址。用户抱怨内容加载速度极慢,因为被匹配到了地球另一端的IP地址,这确实是个问题,尤其是在其他DNS提供商上很少发生这种情况。也许有办法解决这个问题,但我承认我选择了更简单的方案,即回到老牌的8.8.8.8
不,这是故意未实现的:
https://developers.cloudflare.com/1.1.1.1/faq/#does-1111-sen…
我也在使用1.1.1.1多年后改用了9.9.9.9和8.8.8.8,因为这里的网络连接不太好,连接到错误的数据中心会导致RTT超过300毫秒,导致网页加载非常缓慢。
如果 9.9.9.9 无法解析,该设置会回退到 8.8.8.8 吗?
Quad9 采用非常严格的屏蔽政策(我的网站因用户上传内容被封禁,甚至未报告恶意内容;但若为知名品牌,似乎允许用户上传内容),这可能是一个绕过方案,但它可能不会将 nxdomain 响应视为解析器故障
这取决于你更信任谁来处理你的 DNS 流量。我知道我更信任谁。
谁?诚恳地问
现实点说,要么你忽略隐私问题,设置路由到多个提供商,优先选择最快的,要么你完全投入隐私,通过 Tor 桥接路由 DNS。
不过,或许在外部VPS上部署DNS代理能作为折中方案?
如果你是技术型用户,可以本地运行Unbound(甚至在Windows上),并让其通过DoT转发查询。无需使用Tor或自行运行外部解析器。
折中方案就是ISP的DNS,对吧?
如果隐私是你的首要关注点,我100%信任Cloudflare或Google,而非美国ISP。
我自己?递归解析器维护成本低,且能减少暴露于ISP审查(即使在“发达国家”也存在)。
Quad9,dns0。
Google会向你展示广告,而CF不会。
这并非阴谋论——当我们在一个小型、有意识的群体中进行测试时,情况非常可疑。流量看起来并未在谷歌端以匿名方式处理
除非隐私政策最近有所更改,否则谷歌不应利用8.8.8.8 DNS查询进行任何不当行为。
是的,他们并没有长期违反隐私法规、在所有免费产品中收集用户活动数据的记录……
他们也不应该处理我们的 Gmail 数据。这并没有阻止他们。
[需要引用]
阅读他们的服务条款。
如果在服务条款中,那么“[他们]不应该对我们的Gmail数据做任何事情”这一说法就不成立。
CF 因其糟糕的验证挑战破坏了半数网站,这些挑战在许多非主流浏览器(甚至基于 Chromium 的浏览器)中均无法正常工作。
如果你的互联网连接出现问题,你可能会暂时去做其他事情。我强烈怀疑大多数人在那段时间并未更换 DNS 提供商。
他们会在后面详细说明,听起来是部分服务器需要更直接的干预
> 值得注意的是,事件后流量并未完全恢复到正常水平。
客户端会缓存DNS解析结果,以避免每次发送请求时都进行查询。部分客户端可能在相当长一段时间内保留了缓存。
令人惊讶的是,1.1.1.1和1.0.0.1都受到了同一变更的影响
也许现在我们应该开始使用完全不同的提供商作为 DNS 备份,比如 8.8.8.8 或 9.9.9.9
1.1.1.1 和 1.0.0.1 由同一服务提供。它并未被宣传为冗余的完全独立的备份或其他类似功能…
等等,那为什么1.0.0.1存在呢?我承认我从未见过它被宣传或记录为备用地址,但我只是假设它一定存在,否则为什么要有两个呢?(既然1.1.1.1本身就不是单一节点,所以我认为不需要第二个IP地址来实现负载均衡。)
我不知道这是不是原因,但inet_aton[0]和其他解析库会将1.1解析为1.0.0.1。我使用
ping 1.1作为快速连接测试。[0] https://man7.org/linux/man-pages/man3/inet_aton.3.html#DESCR…
难道不是因为很多酒店/公共路由器使用 1.1.1.1 作为 captive portal,因此无法使用 1.1.1.1 吗?
输入“ping 1.1”比输入“ping 1.1.1.1”快得多
1.0.0.0/24 与 1.1.1.0/24 是不同的网络,因此可以部署在其他地方。确实,目前从我的笔记本电脑访问 1.1.1.1 时会经过 141.101.71.63,而访问 1.0.0.1 时会经过 141.101.71.121,这两个地址都位于同一 LINX/LON1 对等节点上,但可能来自不同的路由器,因此存在一定的容错性。
考虑到 DNS 是避免单点故障最简单的方式,我不明白为什么要把所有鸡蛋都放在一家公司里,但这似乎就是现代互联网的现状——优先集中化而非冗余,因为冗余被认为是困难的。
> 输入 ping 1.1 比输入 ping 1.1.1.1 快得多
我猜是这样。我原本以为为了节省4个字符不值得,但确实如此。
> 1.0.0.0/24 与 1.1.1.0/24 是不同的网络,因此可以部署在其他位置。
我以为任播技术可以在单个 IP 上实现这一点,不过也许这种方式更具弹性?
我不是网络专家,但任播技术会根据你的位置提供不同的路由。而拥有两个 IP 则可以在同一位置提供不同的路由到这两个地址。在这种情况下,由于错误与 BGP 相关,且他们显然使用相同的系统来宣布这两个 IP,因此两者均受到影响。
在互联网世界中,你无法真正广告小于/24的子网,因此1.1.1.1/32不是一条路由,而是通过1.1.1.0/24转发。
你可以看到它们是独立的路由,例如查看Telia的路由IP
https://lg.telia.net/?type=bgp&router=fre-peer1.se&address=1…
https://lg.telia.net/?type=bgp&router=fre-peer1.se&address=1…
在这种情况下,它们都来自同一个上层对等节点,我怀疑通常都是这样——它们确实来自同一个自治系统(AS),但并不一定非要如此。你可以有两个使用Cloudflare的对等节点,每个/24子网都有不同的权重
因为操作系统有两个用于DNS服务器IP地址的字段,而Cloudflare希望出现在这两个位置。
一般来说,DNS设计的理念是使用离你最近的DNS解析器,而不是由最大公司运营的解析器。
不过,建议您有针对性地选择不同地区、不同骨干网、不同服务商的多个解析器,并且不要使用Anycast地址,因为Anycast可能会出现一些异常情况。然而,这可能会导致难以排查的问题,因为DNS并不总是按照预期方式运行。
您对如何找到离我最近的 DNS 解析器的建议是什么?我目前使用 1.1 和 8.8,但对其他选项持开放态度。
离您最近的 DNS 解析器是由您的 ISP 运行的。
实际上,它距离我的左肘约20厘米,这在物理上比ISP运营的任何服务器近几个数量级,逻辑上至少也近两个网络跳跃。
而对我大多数机器而言,最近的解析代理DNS服务器正监听其回环接口。最近的此类机器恰好距离约1米,因此以厘米之差屈居第二。(-:
遗憾的是,微软随意将此类功能绑定到Windows服务器版本,而未在工作站版本中提供,但其他操作系统并未受到如此人为限制或束缚;即使是这些系统上的新手用户,也能直接获得一个无需系统管理员动手配置的可工作代理DNS服务器。
认为必须依赖ISP,甚至依赖CloudFlare、Google和Quad9来实现此类功能,不过是这些ISP、CloudFlare、Google和Quad9自己散布的营销故事。不依赖这些服务并非仅限于具备系统操作技能的人群(即他们所指的对象),而是受限于用户使用的设备类型:黑盒式“智能”电视等设备,以及微软Windows工作站版本。即便对于此类设备,用户仍可选择质量较好的路由器/网关,或在局域网内部署提供代理DNS服务的小型设备。
在我的情况下,这个小盒子大概和我手掌大小相当,比我常用的SOHO路由器/网关还要小。(-:
考虑到缓存命中率会随着用户数量增加而提升,这样做在延迟方面真的有优势吗?
是的。如果延迟很重要,可以始终通过局域网聚合,使用指向单个解析缓存代理的转发缓存代理,并通过相同的机制实现规模经济。但延迟更多是只见树木不见森林的问题。
就我日常使用而言,过去几十年里,缓存未命中延迟大多淹没在庞大的WWW页面、人为的服务灰名单延迟、CAPTCHA延迟等噪声中。
尤其是在任何完全缓存未命中的第一步中,对根内容DNS服务器的后端查询,也只是通过回环接口进行的一次往返。事实上,现在有时这也是第二步,因为一些顶级域名也允许镜像其数据。感谢爱沙尼亚。https://news.ycombinator.com/item?id=44318136
其他领域的收益也相当显著。请记住,隐私和安全也是人们所追求的。
此外,像Quad9/Google/CloudFlare的任播技术,出人意料地经常导致连续查询时命中多个独立服务器,这并未带来表面理解所预期的缓存收益。
出于好奇,我几天前在https://news.ycombinator.com/item?id=44534938上循环执行了Bender的测试。我从Quad9、Google公共DNS和CloudFlare 1.1.1.1这三个服务中,在仅相隔10秒的查询中,收到了多次连续的缓存未命中,导致TTL被重置为最大值。通过一些计算,我可能能够估算出这些服务中有多个独立的Anycast缓存正在从头开始响应我的请求,而实际上并未提供人们天真地认为会发生的缓存命中。
我当然将127.0.0.1添加到了Bender的列表中。它在开始时有1次缓存未命中,之后每次都命中缓存,只是在循环的每次迭代中将TTL减少10秒;尽管它认为42天过长,将其缩短至一周。(-:
请记住,低延迟与可靠性是不同的目标。如果你想要最低延迟,大型公司的任播地址通常会胜出,因为他们已经花费了几百万美元来获取这些地址。如果你想要最可靠的,那么离你最近的跳转节点应该是最可靠的(无法保证系统管理员的水平),这通常是 ISP,但有时并非如此。
如果你在本地网络上运行自己的递归 DNS 服务器(我总是忘记使用正确的术语),你可以直接访问根服务器,这使得它成为最可靠的 DNS 解析器。虽然初期可能会出现更多缓存未命中,但我怀疑你根本不会察觉。(注:直接查询根域名服务器属于不良网络礼仪;你应始终将对根服务器的查询缓存至少5分钟,并始终使用DNS解析器进行本地缓存)
> 如果你想要最可靠的解析,那么离你最近的跳转节点应该是最可靠的(这无法避免系统管理不善的问题),通常是 ISP,但有时并非如此。
我认为,考虑 ISP 解析器管理不善的问题是评估可靠性时的重要部分。
我曾经在家中运行 unbound 作为完整的解析器,最终这是我改回转发到其他大型公共解析器的原因。许多域名似乎在返回首次查询时速度很慢,家中各种设备在初始连接时都出现了奇怪的行为。
改回仅使用大型解析器后,所有这些问题都消失了。
Windows 11不允许使用该组合
最大的公司难道不是最有可能拥有离我最近的DNS解析器吗?
不,你的ISP可能拥有比任何外部服务器更近的服务器。
你的ISP应该有离你更近的DNS解析器。但“应该”并不一定意味着更快。
我遇到过ISP的DNS服务器(通过DHCP配置)比1.1.1.1和8.8.8.8更远的情况。
以丹麦为例,ISP的DNS也意味着内容审查。当然,这始于儿童色情内容(CP),随后扩展到版权、药品、赌博和“恐怖主义”等领域。除了偶尔下载Linux ISO文件外,我并未参与这些话题,但我原则上反对任何形式的审查。当然,这并不能阻止任何人,但政客们可以站在电视摄像机前声称他们在保护儿童和阻止恐怖分子。
不仅如此。互联网服务提供商(ISP)通常受某些数据保留法律的约束。对于丹麦(及其他欧盟国家)而言,这一期限可能为6个月至2年。而考虑到与“九眼联盟”的密切联系,美国可能本就能够获取我的信息。
根据Cloudflare的隐私政策,他们在持有个人可识别信息方面比我的ISP更少,同时提供EDNS和低延迟服务?这简直是三赢。
难道这不是一直以来的情况吗?
我的意思是,我们不是已经这样了吗?
我的两个Pi-hole都使用OpenDNS、Quad9和CloudFlare作为上游服务。
我大多数设备都同时使用这两个Pi-hole。
如果你已经运行了Pi-hole,为什么不直接运行自己的递归缓存解析器呢?
一般来说,不存在所谓的“DNS备份”。大多数客户端只是随意从列表中选择一个,它们不会在故障时切换到另一个。因此,如果一个服务器下线,你仍然会发现许多请求超时。
事实上,要说“大多数客户端”的行为是相当复杂的,因为当DNS客户端库配置了多个IP地址用于连接时,它们的行为会有所不同。虽然可以说在DNS客户端层面,备用和冗余机制并不总是按预期工作,但也不能走向另一个极端,说这种机制根本不存在。
>尽管此次发布经过了多位工程师的同行评审
我感到有些惊讶的是,6月审核原始更改的多位工程师都没有注意到他们将1.1.1.0/24添加到了应被重定向的前缀列表中。我好奇是什么样的人为错误或恶意导致了这一原始错误。
或许在DLS中添加一些硬编码的特殊情况缓解措施是明智的,以防止1.1.1.1/32或1.0.0.1/32被重新分配到单一位置。
这可能简单得多,“我信任杰里,我确定这没问题,已批准。”
我通常更倾向于“责怪工具”而非“责怪人”——这取决于系统如何设置以及配置如何生成,此类变更很容易被忽视,尤其是当大量差异是自动生成的。代码审查仍然由人类进行,这种失败表明流程存在问题,无论是否存在懒惰或愚蠢的行为。
但,是的,这里的第二个缓解措施是深度防御——在理想世界中,所有系统都使用相同的运维/部署等堆栈,在这个系统中,你可能希望在可能导致大型公共服务离线的情况下增加几个额外步骤。
奇怪。根据我从多个网络收集的遥测数据,其实不可用时间远超这个范围。
许多评论者认为DNS提供商之间存在备用行为,但实际上,DNS客户端(尤其是操作系统或路由器级别)很少实现对DoH的健壮故障转移。如果你使用cloudflare-dns(.)com且其服务中断,除非 stub 解析器或路由器明确支持多提供商故障转移(并采用首次使用信任或固定证书模型),否则你将无法使用。DoH带来的冗余假象需要对用户体验进行认真重新设计。
我使用routedns[0]正是因为它几乎支持所有DNS协议;UDP、TCP、DoT、DoH、DoQ(包括0-RTT)。但更重要的是,它具有高度可配置的路由引导功能,甚至可以按记录级别进行配置,如果你愿意承受所有相关的配置工作。它非常健壮且非常实用,我在台式机和服务器上使用1.1.1.1,当事件发生时,我甚至没有注意到,因为故障转移“只是正常工作”。我不得不实际查看日志,因为我没有注意到。
[0] https://github.com/folbricht/routedns
>Cloudflare对服务拓扑的管理经过长期优化,目前采用的是传统系统与战略系统相结合的架构,两者保持同步。
这段文字写得非常出色。既清晰易懂,又兼顾了技术人员和非技术人员的阅读需求。让正在进行的迁移过程听起来比实际情况要有趣得多!
> 我们对此次事件给客户带来的不便深表歉意。我们正在积极推进这些改进措施,以确保未来服务稳定性提升并防止此类问题再次发生。
对于像 Cloudflare 这样严肃且重要的公司而言,这已是最佳表述。向撰写者和审核者致敬,他们没有对内容进行淡化处理。
我无法判断你是否在开玩笑,但“遗留”一词通常由技术人员使用,而“战略”一词则多由市场营销和非技术领导层使用。将两者混用会让两类读者都感到不快。
你几乎无法找到一个产品营销人员,他们不会将所有非自家产品描述为“遗留”产品。
你对那句话感到烦躁吗?
我最近一直懒得设置,只用了Cloudflare的解析器。事后想想,我可能应该在家庭网络上设置两个不依赖上游解析器的Unbound实例,然后就算了。两者同时故障的可能性很低,而且如果我遇到完全的互联网中断(这种情况不太可能,因为我使用Comcast作为主要服务商,T-Mobile家庭互联网作为备用),那么DNS是否解析都无关紧要。
我从未注意到这次中断,因为我的 ISP 会劫持所有出站 UDP 流量到端口 53,并将其重定向到他们自己的 DNS 服务器,以便他们可以应用政府强制要求的审查 🙂
> 值得注意的是,DoH(DNS-over-HTTPS)流量相对稳定,因为大多数DoH用户通过手动配置或浏览器设置使用域名cloudflare-dns.com访问公共DNS解析器,而非直接使用IP地址。
我使用他们的DNS over HTTPS服务,如果没有在这里看到相关问题报告,我根本不会注意到这个问题。然而,这一事件——加上过去的一系列事件(包括最近由第三方故障引发的连锁服务中断)——促使我减少对这些服务的依赖。我不再使用Cloudflare Tunnels或Cloudflare Access,而是用WireGuard和mTLS证书取代了它们。我仍然使用他们的计算和存储服务,但仅限于个人项目。
我好奇1.1.1.1的正常运行时间比率与8.8.8.8相比如何
可能会有明显差异?
我看到关于Cloudflare的停机事件报告比Google的多,但这只是个人经历。
https://www.dnsperf.com/#!dns-resolvers
过去30天,8.8.8.8的可用性为99.99%,而1.1.1.1为99.09%
我猜这取决于你所在的位置以及你如何定义停机。单次查询失败算不算停机?
对我来说,Cloudflare的1.1.1.1和1.0.0.1在过去3个月中的平均响应时间为15.5毫秒,8.8.8.8和8.8.4.4为15.0毫秒,而9.9.9.9为13.8毫秒。
所有这些服务器在我的监控点上,以“给定1分钟时间段内的最差结果”进行量化时,都实现了超过99.9%的可用性,这似乎可以作为上游提供商组合中的选项。个人而言,我绝不会依赖单一提供商。Google实现了99.99%的可用性,但这是基于90天的数据,因此我不会从中得出长期结论。
> 针对同一 DLS 服务进行了配置更改。该更改将一个测试位置附加到非生产环境服务;该位置本身并未上线,但该更改触发了全球网络配置的刷新。
现在说什么?一个测试触发了全球生产环境的更改?
> 由于之前将1.1.1.1解析器的IP地址与非生产环境服务关联的配置错误,当我们更改非生产环境服务设置时,这些1.1.1.1 IP地址被意外包含在内。
你们有一个流程,允许其他服务直接占用生产环境中已被其他服务使用的地址路由?
哦,这解释了很多。我一直遇到随机连接问题,当我禁用 AdGuard DNS(自托管)后问题解决,所以我以为是我的虚拟机出了问题。
这是一份很好的事后分析,但改进只能通过流程变更实现。似乎 CloudFlare 的每个团队都在孤立处理此问题,缺乏集中式问题管理。每周我们都会看到一次CloudFlare的全球性故障。看来变更管理流程存在问题,需要重新审视。
问题:多年前,当我从事网络工作时,Cisco无线控制器内部使用1.1.1.1地址。在我的测试中,它们似乎会直接将发往该IP的通信置于黑洞。我推测当1.0.0.0/8开始在互联网上路由时,他们更改了这一设置?
是的,APNIC向Cloudflare授予这些极具价值的IP地址部分原因在于观察配置错误的规模。
理论上,CF具备吸收垃圾流量而不影响自身网络的能力。
网络配置的一般原则是仅使用你实际控制的IP地址和域名… 但即使在5-8年前,我最后一次亲自操作思科WLC设备时,它仍然硬编码了1.1.1.1。思科喜欢打破自己的规则…
有趣的是,Verizon蜂窝网络会阻断1.1.1.1。我是在尝试使用Linux笔记本的热点功能时发现的,当时我将默认DNS设置为1.1.1.1。
非常令人沮丧。
有趣的副作用,Gluetun 的 Docker 镜像使用 1.1.1.1 进行 DNS 解析——由于此次故障,Gluetun 的健康检查失败,镜像停止运行。
如果能查看种子下载流量,无疑会出现 20 分钟的流量骤降。
个人认为,任何在操作系统之外自行进行 DNS 解析的 Docker 镜像都堪称“特洛伊木马”。
Cloudflare再次出现服务问题并不令人意外。
我在工作中使用Cloudflare。Cloudflare存在许多漏洞,且部分技术决策荒谬至极,例如Worker的cache.delete方法,该方法仅清除Worker被调用的数据中心中的缓存内容!!!https://developers.cloudflare.com/workers/runtime-apis/cache…
根据我的经验,Cloudflare 的支持团队毫无帮助,总是试图将问题推给用户,比如“只要避免以那种方式使用它就行了”。
在工作中,我不得不使用 Cloudflare。下次换工作时,我会明确界定职责范围:我不与 Cloudflare 合作。
我绝不会在家中使用 Cloudflare,也不推荐给任何人。
下周:一篇关于 Cloudflare 如何拯救网络免受大规模 DDoS 攻击的新文章。
> 有些技术决策荒谬至极,例如Worker的cache.delete方法,它仅清除调用该Worker的数据中心中的缓存内容!!!
缓存 API 是从浏览器中借用的标准。在浏览器中,cache.delete 显然只删除该浏览器的缓存,而非全球所有浏览器的缓存。当然可以争论说在 Worker 中进行全局清除会更实用,但这与标准 API 行为不一致,且会极其耗费资源。设计为使用标准缓存 API 的代码最终会比预期昂贵得多。
综上所述,我们(Worker 团队)回顾认为缓存 API 并不适合我们的平台。我们确实希望遵循标准,但该标准在此情况下过于针对浏览器,因此无法很好地适应 Cloudflare Worker 的典型使用场景。我们希望用更好的方案替换它。
>cache.delete 显然只删除该浏览器的缓存,而非全球所有浏览器的缓存。
在我看来,只有当 put 方法仅在调用 Workers 的数据中心创建缓存时,这种设计才有意义。我认为 put 和 delete 需要相关联。
现在我很好奇:清除Worker被调用的数据中心中的缓存内容有什么意义?我无法想到这个方法的任何用途。
我的批评并非针对功能本身或开发人员。我并不怀疑开发人员的竞争力,但我觉得公司文化可能存在问题。
只想说,我一直很欣赏你的评论和坦率!
Cloudflare 当然不是完美的(当他们做出改变破坏现有 API 契约时,总会让我度过几段糟糕的日子),但总体而言 Cloudflare 还是相当可靠的。
不过,我不用Workers也不打算用。我个人尽量避免使用非跨平台的东西,因为过去我曾因供应商/平台锁定而遭受过严重损失。
> 当他们做出改变破坏现有API合同时,总会让我度过几段糟糕的日子
如果我们在 Workers 中更改 API 导致任何生产环境中的 Worker 出现问题,我们会将其视为事件并尽快回滚。我们真的尽量避免这种情况,但有时很难判断。如果未来发生此类情况,请随时联系我们(例如提交支持工单、在 GitHub 上提交 workerd 问题、在我们的 Discord 频道投诉或发送邮件至 kenton@cloudflare.com)。
感谢!为了澄清,问题出在 DNS 记录设置 API 的 API 合同上。我这是凭记忆说的,大概有两三年了,可能有点生疏,但一个例子是 TTL 记录的数据类型接受规则的微小更改。以前,JSON 格式可以接受字符串或整数,但后来开始拒绝整数(或字符串,具体取决于我当时发送的是哪种类型),导致 API 调用突然失败(公平地说,这可能并不严格违反合同条款,但这是多年来一直保持一致的行为突然发生变化,而我对此毫无预期)。另一个问题涉及返回记录中的 zone_id,因为 zone_id 在返回的记录中不再被填充。幸运的是,我的代码已经包含 zone_id,因为它需要该字段来构建 URL 路径,但这导致了一次艰难的调试过程,最终我不得不通过两种方式绕过问题:要么在返回的记录中重新添加 zone ID,要么从我的等值检查中移除 zone ID,这两种方案都不是理想的解决方案。
如果我们开始使用工人,我一定会告诉你如果有任何API更改!
我不知道你们怎么想,但我喜欢一篇写得好的RCA。做得很好。
这就是为什么运行自己的解析器如此重要。Clownflare总会搞砸一些事情或留下后门
我被这个问题困扰过,所以现在dnsmasq同时使用了1.1.1.2、Quad9和Google的8.8.8.8作为主备DNS。
备用DNS本应部署在独立网络中以避免此类问题。
这对我来说相当烦人,因为我大约三周前才将 DNS 服务器切换到 1.1.1.1,以绕过 ISP 的 DNS 故障。如今,一个相对稳定的 DNS 真的这么难要求吗?
如果你使用的是免费服务,那么在出现故障时抱怨是不合理的。
正如其他评论所提,如果你对稳定性不满意,可以自己动手解决。或者直接付费让他人提供服务——比如你的ISP。
说实话,我更信任本地ISP而非谷歌或Cloudflare。不是因为可用性,而是因为本地立法机构对其进行监管。这在积极意义上是巨大差异。
> 它受到我当地立法机构的监管
但在某些司法管辖区这可能不是好事——例如英国的色情内容屏蔽(据我所知是通过DNS实现的,且可轻松通过第三方DNS如Cloudflare绕过)。
是的,它有优缺点,可惜。
到目前为止我比较幸运,唯一知道的封锁是针对赌博的。对我个人来说这没问题。
但在英国的情况下,我也会使用非本地DNS。
> 如果出现服务中断,抱怨是不合理的。
我认为在讨论基础设施时这不公平。抱怨路面坑洼、自来水不可饮用、车管所排长队、人行道破裂(或不存在)等情况是合理的。互联网是基础设施,而域名解析是其关键组成部分。它未被国有化并不改变其基础设施的本质(且访问权绝对应免费),因此所有人都应有权抱怨其运行不畅。
“但你缴纳了税款来获得可饮用的自来水,”是的,我们也缴纳了税款来让互联网正常运行。出于某种原因,一些政府(如美国)认为在税款上增加一个中间商是个好主意,但没关系,我们也会对这个中间商提出投诉。
你可以运行一个递归解析器。有很多包可以安装。根DNS服务器没有受到影响,所以你本来就没事。
DNS是基础设施。但“Cloudflare公共免费DNS解析器”不是,它只是一个便利工具和收集数据的产品。
甚至可以运行一个私有根内容DNS服务器,也不会受到根问题的影响。
(当然,这并非主要问题;我提及这一点只是为了进一步扩展你的论点。私有根内容 DNS 服务器的最大优势在于,由于各种原因产生的大量无意义 DNS 流量可在本地或至少在不经过边界路由器的情况下被过滤掉。这些优势主要体现在安全性和隐私性上,而非可用性。)
你说得对,基础设施很重要。
但与自来水不同,有很多不同的免费DNS解析器可以使用。
而且我不明白我的税款是如何资助CF的DNS服务的。但我的ISP费用涵盖了他们的DNS解析设置。这就是为什么我写道
> 一个免费的服務
而CF正是如此。
DNS 本不应被私有化,因为它是互联网基础设施的关键组成部分。然而,认为某家公司可以出售(或“免费提供”)这项服务本身就是荒谬的,因为该服务在缺乏互联网基础设施(由政府通过税收建设)的情况下毫无意义。我甚至无法想到一个相当的例子,因为这种行为本身就荒谬至极,我最好的猜测可能是,如果房东被允许向你收取在公寓前人行道上行走的费用之类的事情。
DNS并未私有化。这与根DNS服务器无关,只是众多免费解析器中的一个——在这种情况下,是其中较大且受欢迎的一个。
>它没有被国有化并不改变它属于基础设施的事实(访问绝对应该免费),因此每个人都应该自由地抱怨它没有正常工作。
>“但你为可饮用的自来水缴纳了税款,”是的,我们也为让互联网正常工作缴纳了税款。出于某种原因,一些政府(如美国)认为在税收资金上增加中间商是个好主意,但没关系,我们也会对中间商提出投诉。
你不希望DNS被国有化。即使是美国,现在也可能有一半的互联网被封禁。
为什么不使用多个?你可以同时使用1.1.1.1、你的ISP和Google。或者自己运行一个解析器。
>或者自己运行一个解析器。
我这样做了一段时间,但每次DNS解析都卡在~300ms,确实让人很快厌倦。
哎呀。用的是什么解析器?什么硬件?
使用基于N100或N150的单板计算机(大约$200),运行任何开源DNS解析器,我预计冷查询平均约30毫秒,缓存命中低于1毫秒。
这不是硬件问题,而是物理问题。我住在新西兰。我猜根服务器都位于美国,所以每次往返至少需要130毫秒。
它们并不都位于美国。
我原本想回复说新西兰与其他地方的距离几乎与美国相当,但后来发现了一个更有趣的事实:除了澳大利亚和新西兰本地的服务器外,最近的根服务器实际上位于美国,具体在美属萨摩亚,距离新西兰仅3000公里。基本上就在隔壁。(我得回去工作了,不然老板走过来看到我在谷歌地图上闲逛,但我敢肯定下一个最近的在法属波利尼西亚。)
这就是我的经历。显然缓存是启用的(unbound),但大多数DNS保持活动时间都短得对单个用户来说几乎没用。
即使根服务器不在美国,对我来说速度也会很慢。欧洲的情况更糟。亚洲大部分地区到我的路径都很差,只有日本和新加坡稍好一些,比美国好一点。也许澳大利亚有……?
Cloudflare实际上运行着其中一个根服务器(https://blog.cloudflare.com/f-root/)。
根据[0],奥克兰至少有一个。不过我对该网站的真实性并不确定。
[0] https://dnswatch.com/dns-docs/root-server-locations
>DNS保持活动时间过短,几乎毫无用处
无能的管理员。dnsmasq至少有一个选项可以覆盖它(–min-cache-ttl=<time>)
一次故障就意味着1.1.1.1不再合理稳定?你才是那个不合理的人
虽然我同意 1.1.1.1 没问题:但对这位评论者而言,他们在使用 3 周内经历了一次重大故障,这并非良好记录。(理解个人经验优先于他人声称这不具代表性。)
三周内来自两个完全不同的提供商的两次故障意味着,我最近的DNS使用体验比过去20年左右使用互联网时要不稳定得多。
你的个人经历虽有价值,但在此情况下无法推广。我一直使用8.8.8.8和1.1.1.1(备用)从未遇到过故障。
我上网已有30年,从未因ISP的DNS故障受到影响。
当DNS解析器故障时,会影响所有服务,100%的正常运行时间是一个合理预期,因此需要冗余。看起来1.0.0.1和1.1.1.1都停机超过1小时,这相当糟糕,尤其是当你建议全球使用时。
根本原因分析不够详细,感觉像是每隔几周就出现的营销噱头。
我也在线已有30年,经常遇到ISP引起的DNS问题,即使我没有使用他们的解析器……因为他们喜欢进行DNS拦截操作。在我开始运行自己的解析器之前,我曾遇到过ISP DNS解析器的停机问题。这在过去涉及多家ISP。轶事证据很棒,对吧?
在本地运行自己的转发器。Technitium DNS让这变得简单。
我现在在本地运行Unbound作为递归DNS服务器,这本应是默认设置。在现代路由器中没有理由不这样做。
不确定2025年对于任何事情来说, stub解析器的“优势”是什么。
那关于劫持的事是怎么回事?
相关但非因果事件:Cloudflare撤销路由后暴露的BGP源地址劫持事件(涉及1.1.1.0/24前缀)。这并非服务故障的直接原因,而是一个与之无关的问题,只是在Cloudflare撤销该前缀后突然显现。
我对此不太了解——为什么之前压制了另一个 1.1.1.0/24 的公告?是因为它的成本足够高,以至于没有人愿意接手,相比于 CF 的公告?
Cloudflare的路线由RPKI覆盖,该机制通过证书形式化IP地址空间的委托。
导致这种特定行为的原因是BGP安全方面存在的向后兼容性困境。目前,所有路由都由RPKI覆盖的程度还很低(根据https://rpki-monitor.antd.nist.gov/ROV的数据,仅有56%的V4路由被覆盖),因此无效路由通常会被视为优先级较低的路由,而非被支持RPKI的BGP节点直接拒绝。
由于当时在社交媒体上有人指出这一问题,许多人认为虚假路由正是导致故障的原因。
所以有人在前缀可供使用时就开始广告它?这挺有趣的
不,他们早就这么做了,合法路由的全球撤销只是暴露了这一点。
为什么在他们的RCA中完全没有进一步的评论?这似乎是个相当重大的事情…
我以前将1.1.1.1设为主要DNS,8.8.8.8设为备用,但发现Cloudflare整体响应查询更快,于是将所有设置改为使用1.1.1.1和1.0.0.1。或许我会切换回使用8.8.8.8作为备用,不过我理解DNS会在线程轮询模式下在主备服务器之间切换,而非仅在主服务器故障时才使用备用。或许我理解有误。
EDIT:看来我错了,实际上是主备切换而非主备轮询。因此使用1.1.1.1和8.8.8.8是有道理的。
这取决于你的配置方式。例如在resolv.conf系统中,你可以设置1秒的超时并配置为主/备用模式,或设置为轮询模式。据我记忆,配置类似于“options:rotate”
如果你使用了更高级的本地解析器(如systemd),你可以配置任何你想要的行为。
我很想知道他们所指的“传统系统”具体是什么。
或许我过于敏感,但这篇文章读起来像是AI生成的——至少大部分内容经过了模型编辑。
Cloudflare与OpenDNS相比如何?
你最好将其与 Quad9 进行比较,基于性能、隐私声明和响应准确性。
Cloudflare 是美国的一家营利性公司。他们的隐私声明不可信。即使我们相信他们,我们也不知道解析数据是否被美国情报机构获取。
嗯,你在这里试图做出什么区分?OpenDNS 也是美国公司,2015 年被思科(美国公司)收购。
我对 OpenDNS 了解不多,但确实不信任思科做任何不以盈利为目的的事情。我只是提供相关关于Cloudflare的信息。
看来这里有很多Cloudflare的粉丝和辩护者。这并不意外。但我写的内容有任何不实之处,还是只是不受欢迎?那些给我点赞的人是否愿意指出我写的内容中的任何不准确之处?
美国公司向投资者撒谎是违法的,所以如果你认为他们在对你撒谎,你应该以证券欺诈为由起诉他们。
说我最后查看Cloudflare状态页面时感到惊讶,这简直是轻描淡写。
1.1.1.1并非独立运行。
它设计上需与1.0.0.1配合使用。DNS内置了容错机制。
1.0.0.1也宕机了吗?如果是,为什么它们在同一基础设施上?
这对我来说毫无意义。8.8.8.8也有8.8.4.4。整个设计初衷就是它随时可能宕机,但系统仍能正常运行。
难道修复方案不应该是确保这些服务从完全独立的系统中提供,并更新所有文档,以确保使用 1.1.1.1 的用户也配置了 1.0.0.1 作为备用吗?
如果我运营这样的服务,我会定期对主服务器进行停机或部分停机测试,以确保用户的解析器配置正确。没有人应该将单一 IP 地址作为互联网访问/浏览的单点故障。
> 1.0.0.1 也停机了吗?
是的。
> 难道修复方案不应该是确保这些服务从完全独立的隔离环境中提供 […]?
是的。
> 如果是这样,为什么它们在同一基础设施上?
显然,它们不够独立:CF中的一些内容同时宣布了这两个地址,导致问题暴露。
对于最终用户来说,当然的解决方案是使用1.1.1.1和8.8.8.8(或任何其他两个不同的解析器的组合)。
你不需要测试人们的解析器是否能干净地处理这个问题,因为已经知道很多解析器都做不到。跨平台的DNS回退行为是一团糟。
我总体上不喜欢CF,因为他们在互联网服务中的中心化作用。
但我确实欣赏此类详细的公开事件报告和根本原因分析。
Cloudflare 提供了一项服务,旨在阻止不支持 Noscript/基本 (X)HTML 的浏览器。
我知道。