Brave浏览器对其基于Rust的广告拦截引擎进行全面升级,内存消耗降低75%
我们通过迭代重构adblock-rust引擎,采用紧凑高效的存储格式FlatBuffers,实现了这一重大内存里程碑。

Brave对其基于Rust的广告拦截引擎进行全面升级,内存消耗降低75%,为所有用户带来更持久的电池续航和更流畅的多任务处理体验。此次升级使Brave浏览器在所有平台(Android、iOS及桌面端)默认节省约45MB内存,启用额外广告拦截列表的用户节省空间更大。这些性能提升已在Brave v1.85版本上线,v1.86版本还将推出更多优化。
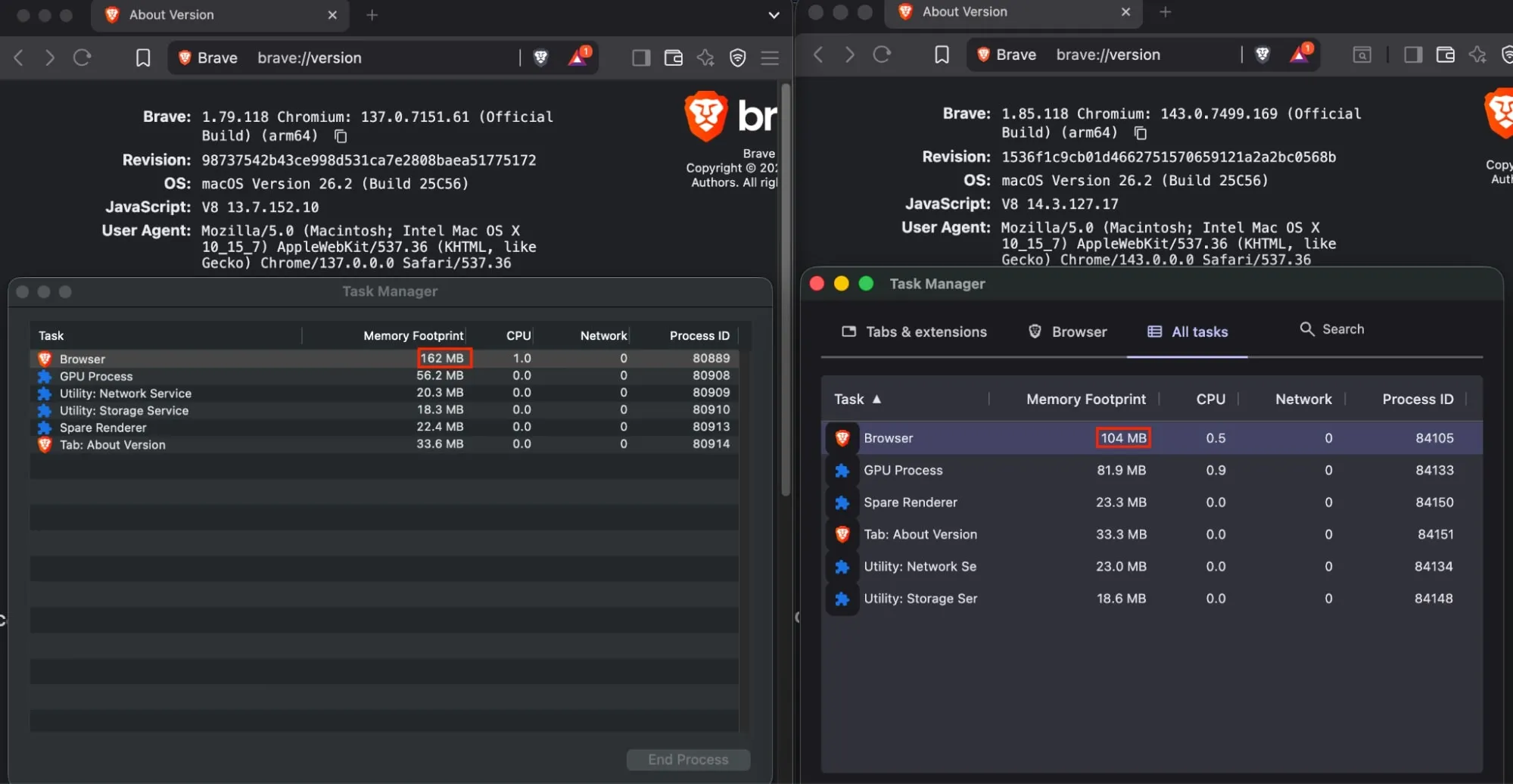
Brave浏览器1.79.118版与1.85.118版的截图对比,显示整体浏览器进程(其中包含广告拦截引擎)的内存消耗有所下降。
正如去年六月和十月所宣布, 我们通过迭代重构adblock-rust引擎,采用紧凑高效的存储格式FlatBuffers,实现了这一重大内存里程碑。此次架构转型使我们得以将默认搭载的约10万条广告拦截过滤器,从标准堆分配的Rust数据结构(如Vecs、HashMaps和结构体)迁移至专用的零拷贝二进制格式。

在此过程中,我们还完成了多项关键性能优化(部分优化将在v1.86版本中推出):
- 内存管理:采用栈分配向量减少19%内存分配,并提升约15%构建速度。
- 匹配速度:通过将常用正则表达式模式分词化,提升过滤器匹配性能13%。
- 资源共享:广告拦截引擎实例间共享资源,在桌面端节省约2MB内存。
- 存储效率:优化内部资源存储内存,提升30%。
节省45+MB内存是浏览器性能领域的重要里程碑,为移动端及老旧硬件用户带来显著收益。尽管Brave通过拦截侵入性广告和追踪器已提升网页性能,但最新工程优化确保了内置防护机制尽可能轻量化且无感运行。与其他浏览器的广告拦截不同,Brave的广告拦截引擎是内置于浏览器核心并由隐私团队维护的。基于扩展程序的拦截器受限于浏览器扩展API和沙盒机制,无法实现如此深度的优化。正是这种原生架构,使Brave的广告与追踪器拦截功能完全不受Manifest V3协议影响。
此次性能提升凝聚了性能团队与隐私团队数月跨部门深度协作的成果,标志着浏览器效率实现重大飞跃,确保我们持续为1亿用户提供业界领先的隐私保护。

本文文字及图片出自 Brave overhauls adblock engine, cutting its memory consumption by 75%,由 WebHek 分享。

Brave的广告拦截引擎堪称开源典范,生动展现了Rust语言中库共享的便捷性。它采用Servo库(Firefox亦使用该库)解析CSS并评估选择器,随后自身作为库发布于crates.io平台,供其他开发者自由调用。
所以Brave有两个CSS引擎?一个用于渲染,一个用于拦截?
是的。因为拦截功能可以使用成熟度较低的CSS引擎,这是性能上的权衡。
公平地说,
selectors库其实相当成熟。它被Firefox用于所有CSS选择器匹配。主要优势在于模块化设计,可单独提取该功能而无需整个CSS引擎。此外,广告拦截过滤器扩展了CSS选择器语法以增加额外功能,你可能不希望这些功能渗入样式表解析器。
我好奇反广告拦截开发者是否会利用这两者的差异
要在远非市场主流的浏览器上绕过拦截机制,工作量实在太大。即便未来该浏览器流行到成为攻击目标,开发者很可能获得足够资源支持,直接替换掉其中一个引擎。
曾在此领域工作过。这无关紧要。
Easylist会主动联系你,强迫你禁用防护措施,否则就威胁要封锁页面所有JS。
因此当用户安装使用Easylist(所有版本)的广告拦截器时,所有广告服务器都无法加载,Prebid等功能将彻底失效。
太神奇了。我原以为广告黑名单是像维基那样靠志愿者维护的。既然知道他们既维护用户权益又惩罚不良广告商,我以后肯定会用Easylist。
说实话这太有趣了,简直是现代版罗宾汉。
这确实是个有趣的经历。
我至今仍不确定这是否最理想的做法。
一方面,这意味着权力集中在少数人手中。
另一方面,其初衷是维护一份黑名单,屏蔽那些消耗资源、侵犯隐私的广告网络和网站横幅。
EasyList团队并非圣人。他们接受谷歌付款允许“可接受广告”。如今用户启用广告拦截器时,广告商只需投放不同广告活动即可。
你大概指的是Adblock Plus?“可接受广告”是他们的项目;EasyList既无此政策也无相关关联。
我主要用EasyList过滤广告,同时启用其他过滤器屏蔽“可接受广告”,这样对我来说效果很好。
我并非暗示没有规避方法。
只是说EasyList间接依赖广告收入(谷歌)
广告问题关乎多数用户群体,他们基本只用默认过滤列表。
哈哈哈 没错这就是现实 活该你们抓狂
那和node/npm面临供应链攻击风险一样吗?
还是说cargo有不同的管理机制(尽职调查?)
你可以用“cargo vendor”命令像C语言那样复制粘贴依赖项,并自行审计所有依赖。Mozilla在Firefox中就是这么做的。
cargo默认确实有锁定文件机制。但要真正解决这个问题,我们确实需要更完善的审计工具(以及确保审计已完成的机制)。
我认为这里更核心的观点在于:C语言式方法是提取依赖项的最小子集,对其进行严格审查并集成到代码中;而Rust/Python式方法则是使用cargo/pip,将依赖项视为项目外的黑盒。
C语言方法的支持者常忽略其增加的维护负担,尤其在安全问题上。本质上,你需要维护一个有限的分支,并独立于上游跟踪CVE漏洞。
因此这终究是权衡取舍,而非绝对优越的解决方案。
此外,Rust本身并未限制你采用相同做法。事实上,我认为Cargo反而简化了这个过程。
但这正是Linux发行版的价值所在——包维护者会为你监控CVE漏洞,你只需执行“apt upgrade”即可。
不太明白。假设你从libxml2中提取部分代码用于HTTP服务器,而libxml2被提交了与该子集相关的CVE。显然你的服务器并未链接libxml2,发行版维护者如何得知要将你的包纳入修复范围?
在归属声明中列出来?
我对发行版打包细节不太熟悉。他们通常会通过归属信息来分发CVE吗?
无论如何,维护负担依然存在。
我认为某些发行版在接受软件包前需要解除供应商标记。
若您隐藏得当,使发行版维护者未察觉您已进行供应商标记,那么攻击者或许也无法发现您正在使用(例如)libxml2库,从而不会将您的软件列为攻击目标。
这假设你使用的是动态链接库/共享库。他们讨论的是将库“封装”为静态链接二进制文件或专属应用程序DLL的做法。
请谨慎对待这个假设。
发行版虽在努力,但遇到立场强硬的项目时会遭遇复杂难题,且可能无法解决。
例如GNOME密钥环的机密信息对运行在您UID下的任何进程开放,除非该进程通过代理访问。
再如所有浏览器和busybox都豁免于apparmor的处理。
将责任推给用户的情况并不少见。
理论上可行,但实践中我认为很难像这样轻松构建Servo这类产品。Servo虽是浏览器,但其设计初衷是成为浏览器开发者的工具包。它具有极强的模块化特性,许多组件(如前述CSS选择器库)都被拆解为独立包,供其他项目复用。此类设计并非Servo独有。
然而安装Servo时,你只需部署单一程序包。无需费心协调不同版本的组件兼容性——Servo团队已完成所有兼容性测试,并将最终成果编译为单一静态二进制文件。
这种设计赋予了极高的灵活性。当维护者需要进行破坏性变更时,他们可以直接实施而不会影响他人。他们内部依赖新版本,但其他项目仍可继续使用旧版本。终端用户和发行版无需担心如何打包两个不兼容的版本,也无需确保正确安装,因为所有内容都是静态构建的。
这种模式贯穿始终。正则表达式库是生态系统中处理正则表达式的标准组件,多数人需要该功能时会直接依赖它。但它不仅是正则库,更是一个由构建正则库所需组件构成的工具包——若你仅需部分功能(如快速子字符串匹配,或不含实现的正则解析器),这些组件均可单独获取。所有组件均由同一人维护,但通过模块化设计使开发者能灵活提取所需功能。
理论上传统发行版包也能实现类似功能,但实际操作中极少见到如此高度的模块化——其复杂性往往成为阻碍。Rust应用可轻松锁定依赖项,仅在必要时(或安全更新需求时)自主升级。但在传统模式下,应用开发者无法确信依赖项会安装特定版本——他们只能信任发行版维护者已组合出兼容的版本组合,且结果能正常运行。一旦出错,开发者还需排查具体涉及哪些版本,判断问题是源于特定依赖组合还是应用本身的普遍问题。
所有这些因素意味着,若采用传统包管理系统的打包分发模式,Servo极不可能以当前形态存在——因为这将为所有参与者带来额外的工作负担。
而主张相反方法的人则创造了如今NPM所处的依赖地狱。
我的意思是,无论使用何种语言,你引入的每个依赖项本质上都在制造这种问题。
关于依赖关系我们得认清现实——不过https://wiki.alopex.li/LetsBeRealAboutDependencies似乎为C语言依赖提供了不同视角。
> C语言式的做法是提取依赖项的最小子集,对其进行严格审查后再集成到代码中。而Rust/Python的做法是使用cargo/pip,将依赖项视为项目外的黑盒。
Rust 的做法是将项目中最小功能子集拆分到独立子库中,使其能脱离主项目被依赖和审计。获取 ripgrep[1] 的引擎[2](该引擎还可进一步拆解以支持更精细化使用)时,无需获取整个项目。
除了具体如何获取并保持依赖代码的更新(包括检查CVE漏洞)之外,检查依赖项代码的工作量大致相同,且随代码规模扩大而增加。多个小型依赖项与单个大型依赖项并无本质区别——只要前者总和接近单体应用的规模。若从单体应用拆分代码,则存在使用方式偏离原始设计意图的风险(例如该代码可能依赖于库中其他部分维护的不变量)。
在我看来,采用能精确追踪依赖版本的系统管理多个小型依赖项,并通过结构化数据实现自动化批量检查,远比“从某个项目复制代码”更符合工程实践。vendoring 模式与规范的安全实践背道而驰(除非另有机制处理vendoring,但此时本质上只是换了个名字的包管理器)。
[1]: https://crates.io/crates/ripgrep
[2]: https://crates.io/crates/grep/
供应链攻击并非依赖管理系统的固有属性
放弃依赖管理系统并非解决之道,审计依赖关系才是
> 审计依赖关系才是
实际操作中如何实现?难道每次执行
brew update或npm update前都要阅读每个包的源代码?若这些源代码包含二进制包呢?
流行的JavaScript React框架拥有1.5万个直接依赖和2千个间接依赖——https://deps.dev/npm/react/19.2.3
一个月内有人能审核完吗?而且他们每周发布新版本。
> 流行的JavaScript React框架拥有1.5万个直接依赖和2千个间接依赖 – https://deps.dev/npm/react/19.2.3
你看到的其实是依赖方数量。React本身没有依赖项。
补充说明:
> 你每次执行
brew update或npm update前都会阅读每个包的源代码吗?是的,必须采取这种做法或委托可信方来完成。(难度应作为选择依赖项的考量因素。)
> 若这些源包含二进制包呢?
要么实现可复现构建,要么别用这些包。
> 您查看的是依赖项数量。React包本身没有依赖项。
确实如此。
我误解了自己分享的链接,在此致歉。
请参考此处的“devDependencies”
https://github.com/facebook/react/blob/main/package.json
据我所知,这些100多个开发依赖默认都会安装。虽然可能规避,但很可能导致构建过程出错,因此多数人仍选择保留默认设置。
> 要么实现可重现构建,要么别用这些包。
许多构建都无法实现可重现/隔离性。就连GitHub Actions也无法保证可重现性https://nesbitt.io/2025/12/06/github-actions-package-manager…
多数前端框架同样无法实现可重复构建。
> 别用这些包。
那该怎么办?
> 据我所知,这些100多个开发依赖项默认都会安装。
开发依赖项仅在开发 React 库本体时才需安装。若仅依赖 React 本身则不会安装这些依赖。
若要审计 React,难道不该审计其构建产物而非源代码?或者也该审计那些开发依赖项?
> 若仅依赖React本身则不会安装这些依赖项。
若理解有误请指正,我的理解如下:
“除非NODE_ENV环境变量设置为production,否则npm install会同时安装依赖项和开发依赖项。”
它不会递归安装开发依赖项。
> 它不会递归安装开发依赖项。
那么,当有人执行
npm install react时,这约100个[直接]开发依赖项就会被安装,对吗?不。只有当你克隆react仓库并在克隆目录内执行npm install时才会安装。
它们仅安装在最顶层包(你正在开发的包)中,npm不会递归遍历所有依赖项并安装其开发依赖。
> ~100个[直接]依赖
执行
npm install react时,直接依赖是react本身。所有react的依赖都是间接依赖。运行
npm install react,看看它声称添加了多少包。(仅一个。)> 然后呢?
继续前进
对于无法直接雇佣工程师团队来处理此事的普通软件生产组织而言,最佳工具是更新禁令机制。默认情况下,您可阻止更新在注册表中停留未满一个月(或其他时限)的软件包,同时允许在必要时设置明确例外。此举能有效防范所有已知的主要供应链攻击。
> 流行的JavaScript React框架拥有1.5万个直接依赖项和2千个间接依赖项 – https://deps.dev/npm/react/19.2.3
您关注的是依赖项。React核心包本身不存在依赖关系。
在安全敏感代码中,应谨慎引入依赖项,对其进行审计,锁定经审计的版本,并仅在严格的时间表(预留新审计时间)或紧急情况下更新。
并非所有依赖项风险相同。具备以下特征的依赖项风险较低:拥有数百万活跃用户、由企业赞助商持续维护、公开安全响应政策并提供服务等级协议(SLA)。而风险较高的依赖项包括:仅有少量活跃用户的个人副业项目、无法联系作者的依赖项,以及迫使你引入大量间接依赖的项目。
以下是针对安全关键型项目的依赖政策示例:https://github.com/tock/tock/blob/master/doc/ExternalDepende…
实际操作中,除非代码涉及极端敏感的安全领域(如信任根),否则无法审查所有依赖项。最终选择的是风险较低的“优质”依赖项。需部署自动化模糊测试和代码检查工具,如今还需借助AI进行审计。
你必须不断权衡:自己犯蠢引入安全漏洞的概率,与引入含漏洞依赖项的概率孰高孰低。当存在经过实战检验的代码时,采用现有依赖通常比自行开发风险更低。
这并非精确科学,必须具体问题具体分析。
若情况果真如此(我对React的数据并不了解),在安全标准合理的项目中,开发者要么只在通过完整验证流程(如行业认证)的版本间迭代;要么干脆因依赖项数量庞大而放弃使用该框架。真正不严肃的做法是抱着“活在当下”的心态盲目引入1.5-1.7万个依赖项。
(没错,我认为99%这样做的JS开发者确实不够认真,但同时我也理解他们只是遵循生态系统推送的“最佳实践”——当整个生态本身都不够严谨时,多数人自然不愿逆流而行)
> 实际操作中该怎么做?难道每次执行
brew update或npm update前都要阅读每个包的源代码?实现方式有多种。你提到的属于暴力型安全审计方法,正如你所言可能不切实际。或许存在专门检测源代码安全漏洞的工具。虽然这些工具永远无法做到完美,但能大幅减少人工审核的工作量。
另一种显而易见的方法是众包验证。这可以通过安全公告数据库实现,例如Rust语言的rustsec[1]服务。Rust有工具能利用rustsec的数据进行审计(cargo-audit),甚至可以将依赖树信息嵌入目标二进制文件。其他语言也必然存在类似工具。
> 若这些来源包含二进制包呢?
只要强制执行可重现构建,二进制文件同样可审计。否则便构成明显的供应链风险。这正是发行版和企业倾向于从源代码构建软件的原因。
[1] https://rustsec.org/
多数情况下,比阅读代码更有价值的是探究代码背后的开发者。你能确认作者身份吗?他们在该领域是否具备可信身份和声誉?你查看的是他们管理的包版本吗?人们常因这类生态系统中的包数量而惊慌,但更关键的是:你的依赖树中存在多少不同开发者?他们是谁?如何运作?
(若依赖树中存在被攻破的节点,次优策略是避免使用频繁自动更新的系统。至少延迟数日更新以控制损害范围。Cargo因锁定文件机制不会在构建时自动更新依赖项:需手动执行更新操作)
在多数情况下,比起阅读代码本身,更重要的是了解代码背后的作者。你能确认作者身份吗?他们在该领域是否具备公信力?
但面对供应链攻击时,这未必有效。此类攻击很大程度上是通过被盗凭证传播的。因此即使软件包的作者信誉良好,你仍可能通过该软件包感染恶意软件。
通常只需对比前一版本的差异即可。但确实,当前对小型企业或个人而言并不现实。大型企业正是这样操作的。
我们需要更完善的工具来实现众包协作,让所有人都能轻松参与。
> 大型企业正是这样操作的。
有人在亚马逊开发者社区提交了恶意代码。
AWS曾发布过恶意版本的自有扩展。
https://aws.amazon.com/security/security-bulletins/AWS-2025-…
我对Node了解不多,但Cargo的锁定文件通过哈希值防止依赖替换,除非开发者主动更新锁定文件。更新锁定文件的风险与最初选择依赖项时相当。
编辑:我误记了Rust仓库的功能(安装前后钩子),因此前文评论既无用又误导。
Rust仓库在构建/安装阶段运行任意代码的频率远高于npm包。
部分用户采用’pnpm’,该工具仅为白名单中的子集包运行installScripts,因此相当比例的npm生态系统(使用pnpm而非npm或yarn的用户)默认不执行脚本。
Cargo会为所有依赖项编译并运行
build.rs,目前尚无真正替代方案能规避此行为。Rust 仓库可在构建时执行任意代码:https://doc.rust-lang.org/cargo/reference/build-scripts.html
> 构建脚本通过向标准输出打印内容与 Cargo 通信。
天啊。
为此专门编写了一个仓库来清理这个混乱局面(并为 build.rs 提供类似 autoconf 的传统功能):https://crates.io/crates/rsconf
谢天谢地,太感谢了。
过程式宏和 build.rs 难道不是在构建时执行的任意代码吗?
基本就是。而且它们在隔离性方面相当薄弱。说实话有点可怕。
当然它确实解锁了某些有趣的可能性,比如sqlx的宏能在编译时连接数据库检查查询语句。听起来像是编译器在连接数据库?没错,它确实如此。
然而Rust生态几乎扼杀了运行时库共享机制,不是吗?这种设计理念认为每个程序并非供维护者使用的系统构建块,而是最终产品,因此在开发阶段就通过静态链接指定具体依赖版本。甚至同款应用的多个工作进程都无法共享内存中的通用代码库,比如库文件、UI工具包、多媒体解码器等,对吧?
附注: 其实我愿意冒风险分享自己(作为Rust新手)的看法:https://shatsky.github.io/notes/2025-12-22_runtime-code-shar…
作为用户和开发者,我最讨厌在运行时遇到依赖和库错误。光是解决程序的运行时依赖问题,我就耗费了无数小时甚至数天——先是无法加载库X,修复后又无法加载库Y,接着库Z版本不匹配,最后还得应对glibc冲突,如此循环往复。
我愿意用一吉字节内存来换取永不再经历这种折磨。
若我没记错,Rust并不支持任何形式的动态链接或库加载。
我接触过的社区成员大多热衷于嵌入脚本引擎或WASM。基于WASM的插件开发正呈现强劲势头。
若我没记错,这既是Rust也是Go的弱点
> 若我没记错,Rust不支持任何形式的动态链接或库加载。
Rust支持两种动态链接:
–
dylib库类型创建使用Rust ABI的动态库。但这类库仅限于单个项目内部使用,因为编译时仅保证与依赖它们的库兼容。– 带
extern “C”函数的cdylib库类型;这会生成典型的C式共享库,但需在Rust的C样式不安全子集中实现完整接口。两者都不理想,但若你执意要编写共享库,确实可行,只是体验欠佳。这正是人们常倾向于使用脚本语言或WASM的原因之一(另一原因是脚本语言和WASM默认具备沙箱机制,安全性更高)。
我还想指出一个常见误解:似乎认为Rust应该允许任何crate编译为共享库。这因一系列技术原因无法实现,任何解决方案都必须像C++的头文件库那样,区分“仅源代码”crate与可编译为共享库的crate。
它确实支持动态库,但几乎所有重要的Rust软件似乎都未考虑此特性进行开发。
Rust的ABI(区别于C的ABI)动态库在编译器/构建环境变更时极其脆弱。尝试在不同构建间实际替换它们几乎无法实现。因此动态库的核心优势(跨构建共享代码、单独更新依赖项)基本无法实现。
它们真正有价值的场景是:当你需要分发多个共享底层代码的二进制可执行文件,且希望节省最终安装的磁盘空间时。据我所知,标准Rust工具链构建正是为此目的而使用动态库。
没错。我正在用Bevy开发游戏。该引擎支持开发期间动态链接以缩短编译时间,效果极佳。
认为C++库能神奇解决ABI问题的观点恰恰是问题的另一面。我曾多次提交错误报告:某些包使用预编译库时误用C ABI,导致(拥有权)对象跨越ABI边界,最终引发堆内存损坏(运气好的话只会出现段错误)及其他更隐蔽的海森堡错误。
Rust确实通过cdylib支持C ABI(区别于不稳定的dylib ABI)。该机制应用广泛,尤其在FFI领域。典型案例是Rust中使用PyO3实现的Python模块[1]。
[1] https://pyo3.rs/v0.15.1/#using-rust-from-python
没错,但绝大多数crates无法这样使用。你必须创建独立的非安全C ABI,再在调用方使用。从开发体验来看,这就像你的依赖库是用C编写的,而你不得不编写安全的封装层。
C++存在相反的问题——人们总以为动态或静态链接任何API都没问题。但若不满足两个条件:a) 意识到ABI屏障的存在,b) 遵守其规则,就无法跨越ABI边界。
当所有资产都使用相同工具链(相同选项)编译时你或许能侥幸过关,但当你遭遇连自己和包作者都未曾察觉的ABI问题时,绝对会抓狂。
Rust的ABI明确处于不稳定状态。虽然有社区项目尝试实现动态链接,但大多不值得投入精力。
此说法有误。Rust原生支持动态链接。否则如何为Python等脚本语言创建模块(使用PyO3)[1]?其采用稳定的C API(cdylib)。
[1] https://pyo3.rs/v0.15.1/#using-rust-from-python
内存很便宜对吧?
至少在设计这个东西的时候是这样…
但这真是内存问题吗?据我理解每个进程都会在独立内存空间加载共享库,所以本质上是ROM/硬盘空间问题。
若停止使用共享库,每个应用程序都将在内存中拥有独立副本…
问题在于存在漏洞的依赖项,以及修复漏洞时需要更新数百个二进制文件。
Go支持插件(本质上是库),但存在诸多限制。你也可以
两者都能链接C库。理论上可以创建带C接口的Rust库并从Rust加载,但显然效率低下
使用不稳定Rust ABI的动态库称为`dylib`,而采用稳定C ABI的则称为`cdylib`。假设定义了稳定版Rust ABI,那么遵循该接口的动态库存在系统中的意义何在?只有Rust能打开它,而系统共享库传统上期望通过C ABI和语言特定的封装器跨语言工作。由此延伸,这影响所有比C更复杂的语言。为什么这会被视为Rust的缺陷?
Go绝对支持动态库
我指的不是macOS上的Dylibs,而是从任意目录加载二进制库并直接使用,无需将其编译进程序。
时隔许久才重新研究这个,所以想明确说明我的意思。不过要是搞错了,我反而会很高兴
这两种语言都完美支持。Go通过cgo实现该功能已有十余年历史。
你仍需编写接口代码,但这适用于所有语言。
按此逻辑,Rust同样支持动态链接。实际上它更胜一筹——这种方案在性能损耗上(若实现得当)比cgo的固有特性更小。
Rust确实支持动态链接,只是(目前)尚未提供稳定的ABI。因此你需要通过动态链接桥接使用C语言FFI,或者确保所有链接库都使用相同版本的Rust编译器编译。
没错,它就是为此而设计的
在采用副本复制(CoW)机制的现代操作系统中,同一应用的多个工作进程默认会共享代码段。
分叉时的副本复制机制已有数十年历史。
即使两个库共享源代码文本,你也无法对它们进行副本复制。
并非如此?只需定义稳定的ABI接口:通过
[repr(C)]等FFI机制实现——这些技术自语言诞生起就存在。无论是调用运行时库的代码,还是编写运行时库本身,它都能完美处理。不过Rust开发者通常更倾向于在Rust内部编程,因为FFI会牺牲大量安全性(通常如此),且构成优化边界(对多数场景而言)。而这两点正是人们选择Rust的核心原因。因此绝大多数代码仍采用静态编译。这种方式更易构建(如同所有语言),除非存在动态化的必要理由,否则通常更受青睐。
当前动态库的实现简直是一团糟,我更倾向于全部静态链接。但理想状态下,我期待探索混合方案:在二进制文件内为库代码添加标记,当操作系统检测到多个应用程序使用相同版本库时,避免内存重复加载。此设计还能在绝对必要时支持库更新,无论是通过运行时机制还是包管理器实现。
操作系统通常已将重复代码页视为去重机会。代码页无需特殊处理,因为系统还会发现看似只读的运行时堆内存重复(例如跨站点共享的JS代码JIT页)。
一个挑战在于:两个随机二进制文件生成相同源库代码页的可能性(即使精确定位到源文件)可能受限于链接器和编译器选项(如死代码清除、优化设置差异、LTO、PGO等)。
共享库的效益通常有限,除非使用的是几乎所有二进制文件都可能链接的库——而随着软件生态日益多样化与复杂化,这种可能性已显著降低。
我认为NixOS式的“构建时绑定”才是解决方案。尤其在Rust中“能编译即能运行”。软件通过库形式共享代码,但任何基于特定库版本构建的软件集,将永久使用该具体版本(直至更新替换为基于不同库版本的新构建)。
你提出的方案行不通,因为若编译器和链接器不做额外努力(据我所知目前不存在),同一静态库在同一可执行文件中链接时不可能存在完全相同的内存页。而一旦允许独立更新,又会重蹈动态库的所有弊端。
在嵌入式系统之外,这种复用对整体系统而言本就只是微不足道的内存节省。对于配备千兆字节内存的系统,动态库的核心优势在于:可更新通用依赖项(如OpenSSL)而无需重新下载系统中所有二进制文件。
况且,绝大多数库文件不都会因死代码消除而被移除吗?实际使用的代码也会在适用场景下被内联,因此根本无需重复数据消除。
你描述的并非静态链接,而是将动态链接库嵌入另一个二进制文件。
个人认为动态库简直是垃圾堆大火,因为它们常被用作提供外部接口的手段,而非单纯共享通用代码。
我希望使用共享库的标准方式是:将程序需要动态链接的.so文件与程序二进制文件一同分发(使用RUNPATH机制),而不是期望它们全局存在(是的,我指的是所有共享库,包括glibc——实际上首先就是glibc)。
这样既能避免可移植性问题,又能获得与静态链接相同的优势——无需额外配置即可原生支持glibc(而非强制使用musl),同时还能借助文件系统级重复数据删除(如btrfs)节省磁盘空间和内存。
> 但Rust生态系统实际上扼杀了运行时库共享,不是吗?
确实如此。如今我们拥有的内存容量虽比1970年代增长了数百万倍,但优秀的库开发者数量远未达到同等增长,因此这可能是合理的权衡。
静态链接终究优于为单个应用打包整个容器(而这似乎正是当下主流做法!)
Adobe Acrobat Reader如今体积竟超过了Encarta 95……天啊,它可能比整个Windows 95还庞大!
完整容器甚至Chromium在Electron中
C早已解决这个问题:模板代码仅在使用处实例化,因此C中会随机混杂哪些内容进入独立共享库、哪些进入使用该库的应用程序。这使得ABI兼容性在实践中极其脆弱。
而且越来越多的C++库采用纯头文件设计,意味着它们始终采用静态链接。
据我所知,Haskell(至少GHC实现)与Rust处境相似:缺乏稳定的ABI。(但我不精通Haskell,可能有误。)
C语言在此实属特例。
这对安全性极具危害。
这不仅关乎内存。我希望拥有稳定的Rust ABI来构建安全的插件系统。大型二进制文件也可拆解为动态库,通过牺牲部分优化来大幅加快重建速度。这在现有半稳定版本的ABI下即可实现——新应用构建仍能加载旧版库。
动态库的主要问题在于系统级共享。这点我们可以避免。但在应用层面它们依然非常有用。
> 我希望拥有稳定的Rust ABI来构建安全的插件系统
稳定的ABI确实能构建更健壮的Rust-Rust插件系统,但我不会将其视为“安全”;动态链接本质上就是不安全的。
> 大型二进制文件也可拆解为动态库,虽会牺牲部分优化,但能大幅加快重建速度。
单个项目内已可通过 dylib 仓库类型实现此功能。
动态库加载可能因多种原因失败,但一旦加载并验证通过,其安全性不应低于常规仓库?
可通过校验混淆符号匹配性,并使用结构体/枚举的哈希值静态表确保布局一致。这能覆盖低级ABI(尽管仍需信任生成混淆符号和静态表的编译器)。
更棘手的问题在于确保泛型类型的匹配性。例如若声明的结构体包含泛型函数与具体函数,且存在私有字段/方法,这些私有细节(当前对版本兼容性无关紧要)将影响ABI稳定性。前文提及的映射表可能不足以保证兼容性:行为变更可能破坏数据解析机制。
因此至少这将重新定义语义版本兼容变更的范围,使其变得更为严格,同时自动化检查(如 cargo-semverchecks 所实现的功能)也将更难实现。作为 Rust 开发者,我并不希望看到这种情况。
你验证的是哪些属性?ld.so/libdl 提供的信息仅限于“这些符号存在/缺失”。
令人惊讶的是至今尚未出现社区分叉版Brave,将其商业组件(奖励系统、AI功能、自有更新机制)全部移除,使其能被主流自由开源Linux发行版纳入软件仓库。
大规模运行浏览器涉及相当高的成本。Brave正致力于提供名为Brave-origin的解决方案来实现您提及的功能。
Brendan在此处对此有更详细说明:https://x.com/BrendanEich/status/2006412918783619455
这确实是个好消息,但我对以下内容感到困惑:
“”"
Brave Origin版本特性:
1/ 全新可选独立构建版本(精简版,不含遥测/奖励/钱包/VPN/AI功能);
2/ Linux平台免费,其他平台需一次性购买。
“”"
那么精简版(至少非Linux版本)不会开源吗?
开源软件可以出售牟利。例如红帽公司销售预装RHEL系统的光盘,定价相当高昂。自行编译则免费,但若想获得即用版就得付费。
或者研究如何从源代码自行编译。但懒人税是必然存在的——尤其针对Windows用户(毕竟在Linux上编译源代码通常便捷得多)。
或许这就是Linux上免费的原因!
开源 ≠ 免费二进制文件
要求分发源代码的规则并不要求分发二进制文件。
我认为这提议相当合理。
正如其他人所言,开源软件可以转售。我书架上就放着整箱Linux发行版。
我愿意为浏览器支付月费,只要它不再把我当作产品,并尊重我的隐私。
这些功能几秒就能禁用。既然客户端运行的所有代码都是开源的,就没有理由不包含这些功能。如果发行版只提供无商业利益的软件(这有什么意义呢?),那只会变成一堆无人维护的业余项目,根本无法使用。
你真的该试试https://flathub.org/en/apps/com.brave.Browser
深表赞同。我使用Brave是因为它拥有出色的广告拦截器且整体运行流畅。安装时取消勾选所有钱包/AI垃圾功能是可接受的代价,但如果有人要推出Braveium,我立刻就会用它。
它的广告拦截器能和uBlock Origin媲美吗?
它更胜一筹(尤其比Manifest V3版本强),因为它具备第一方访问权限/集成能力。
总体而言,在第三方拦截器中,uBlock Origin甚至不是最强的,AdGuard才是。
> 总体而言,在第三方拦截器中,uBlock Origin甚至不是最强的,AdGuard才是。
为什么?我以为Firefox上的uBlock Origin搭配相同过滤列表已是现有最有效的组合。
人们反复强调“uBlock Origin + Firefox最优”的主因在于:CNAME反伪装功能在多数Chromium浏览器上失效,即使在Manifest V2环境下亦然。唯Brave浏览器例外。
AdGuard表现更优,根本原因在于其拥有专业团队持续投入开发。优化更彻底、漏洞更少,界面设计也更为精良。其屏蔽列表采用改进的语法结构,且更新频率更高以修复网站兼容性问题。EasyList的列表即使在Github上被报告数月仍存在兼容性缺陷,而向AdGuard报告相同问题往往数小时内就能修复。他们还开发了AdGuard Home等关联项目(类似商业版Pi-Hole)。
顺带一提,广告拦截领域的大咖们也为这些公司效力。据我所知,FanBoy(EasyList + EasyPrivacy + 其自建列表)正接受Brave的付费维护。某种意义上,Brave正在为全民广告拦截提供资金支持 🙂
可添加与uBlock相同的列表。我多年未见广告,效果确实可靠。
这不正是Helium在做的事吗?我日常使用它半年了,效果绝佳。唯一希望改进的是1Password的集成体验。
Helium基于ungoogled-chromium开发,通过撤销谷歌的部分代码变更来启用manifest v2。因此若谷歌彻底移除manifest v2,Helium也将失去对UBlock Original的支持。
移除manifest v2支持本身也是可逆的代码变更。当然,变更幅度越大,未来维护所需的工作量就越大。
安装Brave后可一键隐藏bat文件
Linux发行版不会托管商业组件的代码。能否隐藏无关紧要,关键在于这些代码本身存在
但他们对Mozilla却毫无异议?
Mozilla本身不含商业组件。他们确实从谷歌获得默认搜索引擎合作费,且构建的二进制文件会发送遥测数据,但Linux仓库中的版本通常会通过补丁移除或禁用遥测功能。
多数发行版支持通过安装后启用附加仓库来安装专有软件。
对于懂行的技术用户确实如此。但我不建议向技术能力较弱的亲友推荐Brave,因为他们很可能被Brave界面中的某些暗黑模式所欺骗。
即便是目前最优秀的Firefox,每年也会因某些争议性决策令人失望。不过它仍是我的首推选择。
虽然烦人,但Brave的移除操作相当简单,每次安装只需处理一次。
就我所知,这更多是Brave经历审核流程和独立构建的问题,而非单纯关闭烦人功能。
确实。这基本相当于让它们进入Debian主仓库。若成功,那才是真正的自由。
162降至104并非75%的减少…谁会这么计算减少百分比?!
“Brave对其基于Rust的广告拦截引擎进行了全面改造,将内存消耗降低了75%”
此声明仅指广告拦截引擎的内存使用量减少,而非浏览器整体内存消耗。
公平地说,他们声称广告拦截引擎的内存占用减少了75%,而展示的截图似乎是浏览器主进程整体情况(我猜?我不使用Brave),其中广告拦截引擎只是组成部分之一,但对整体占用产生了显著影响。
没错。
感谢澄清。这45MB的减少是整个浏览器的总量?还是每个标签页的节省量?
我猜是同一类人——那些分不清0.002美元和0.002美分区别的人(http://verizonmath.blogspot.com/2006/12/verizon-doesnt-know-…)。
我刚发现Brave浏览器支持垂直标签页功能,https://brave.com/blog/vertical-tabs/
看来我得考虑从Firefox切换了…
Firefox的强大之处在于其扩展功能,对吧?Sidebery[1]很早就实现了稳定的垂直标签页功能。在它流行之前,Tree Style Tabs[2]也是非常全面的解决方案。
但如今从Firefox v136版本起[3][4],垂直标签已成为原生功能,至少基础需求无需依赖扩展。
[1]: https://addons.mozilla.org/firefox/addon/sidebery/
[2]: https://addons.mozilla.org/firefox/addon/tree-style-tab/
[3]: https://news.ycombinator.com/item?id=41192118
[4]: https://news.ycombinator.com/item?id=43254871
它们支持嵌套标签吗?这样能让视觉导航大量标签变得轻松许多。
遗憾的是不支持,但它支持标签分组功能——我正是为此而使用该功能。不过无法实现分组内的子分组。
Firefox有垂直标签页…
这正是我使用FF的唯一原因,加上它比Chrome更强的广告拦截支持,以及某些高级网络隐私功能。
不过它目前尚未原生支持分层(“树状”)标签页。设置里有个占位开关功能。
Firefox 136其实支持垂直标签页
[已删除]
布伦丹·艾奇为何是个混蛋?
他在2008年支持了加州第8号提案(该提案最终通过)。许多人认为这是不可原谅的,这也是后续所有围绕艾奇争议的主要根源。
自从安装Brave浏览器后,我在iOS和Mac系统上都没见过广告。对我来说,这款浏览器运行完美。
你之前用的是什么?我在Firefox加装uBlock Origin后也从未见过广告。实在难以想象Brave能带来多大的使用差异。
过去二十年美国记者数量锐减约80%。不过你尽情享受无广告体验吧!
希望这能促使开发者重新重视资源高效利用,尤其在浏览器领域。
Rust语言应用越广泛,AI就越能为人类编写出优秀的代码…我愿意保持乐观。
我认为标题中的Rust部分在此情境下只是偶然因素。此前资源消耗更高的版本同样是用Rust编写的。
确实如此,但使用Rust的团队通常会更注重资源利用效率。
我同意标题确实有些误导性,真正的更新在于他们采用了Flatbuffers技术。
我也这么认为。
不过Rust似乎既非促使开发者关注内存效率的必要条件,也非充分条件。
理论上并非必需,但实践中关注内存效率的开发者选择本就有限。
若同时追求内存安全,选择范围将进一步缩小。
>我希望这能成为开发者重新重视资源高效利用的起点,尤其在浏览器领域。
人工智能或许迫使了这一转变。由于2026年DRAM行业的大崩盘,用户将无法再通过硬件升级来补贴软件性能。
广告拦截器早已用Rust语言编写。
我喜欢Brave浏览器,但移动端缺乏扩展功能是阻碍我使用的唯一因素。因此在安卓设备上,Firefox仍是我的日常主力浏览器。
最近我将安卓端的Firefox切换为Brave。速度快得多,虽然缺少扩展,但内置功能完全满足我的需求:- 强制深色模式 – 广告拦截
最近发现了Cromite浏览器,真是太好了!终于找到了替代Kiwi浏览器的选择。在安卓设备上它甚至比Firefox和Brave都更快(当然个人体验可能不同)。
它来了。https://x.com/brave/status/2008244198060028063
而我在iOS端只能用Brave启用广告拦截,Firefox却不行。
天杀的,这种垃圾化现象从未如此泛滥。当前跨平台/跨设备统一配置简直是天方夜谭。
Kagi的Orion在iOS上表现不错,支持火狐/Chrome扩展
勉强算吧,但其实不然——uBlock Origin应用在Orion上无法运行。我对比过Kagi+uBlock与Brave内置广告拦截器的效果,Brave的性能明显更优。
顺便提下,Orion使用的是原生扩展程序,而非你可能指的Safari版uBO Lite应用。
确实如此,我尝试过的扩展程序均未达到预期效果。
或许显而易见,但我仍需简要说明FlatBuffers优于Protobuf/Capnproto/…的理由。
这是每个标签页45MiB吗?大家都在笑话这事,但如今每个标签页都是独立进程…
得益于站点隔离机制,如今每个标签页可能运行十几个甚至更多进程。
这些可能是主广告拦截进程的分叉副本。如果是这样,就能享受CoW内存复用带来的重复数据消除效益。
Windows(明智地)不支持进程分叉。
共享内存显然存在,且他们在帖子中提到(我最初没注意到)会尝试共享广告拦截资源。
就算他们能将内存占用削减110%,让我的可用内存变大,我依然不会信任他们。他们偷吃饼干罐里的手已经伸得太多次了。
与此同时Firefox不断自毁声誉。如今网络浏览真的没有完美解决方案了。
能详细说明吗?
> 2020年,该公司被发现会在用户浏览器地址栏输入的某些加密货币交易所网址末尾添加联盟推荐代码。该做法涉及币安、Coinbase等交易所,后又被发现延伸至“比特币”、“以太坊”等关键词的搜索建议功能。
> 2022年,Brave因将付费虚拟专用网络(VPN)产品“Brave防火墙+VPN”捆绑安装至Windows浏览器而再度受批,即便用户未订阅该服务亦无法避免
https://en.wikipedia.org/wiki/Brave_(web_browser)#Privacy
这可不是散布恐慌的套路
Brave至今仍是加密货币操纵骗局的幌子吗?
从来不是。
或许不是加密货币骗局,但他们确实花了两三年时间偷偷在你的Windows机器上安装自家VPN服务,且不提供退出选项。更可笑的是,当用户运行Brave卸载程序后,这些服务、Windows后台进程和多个计划任务竟都未能被彻底清除。
最精彩的是——当他们终于承认问题存在(此前还矢口否认呢哈哈)后,这个骗局在GitHub上悬而未决长达数月。
这大概是我见过最接近病毒的浏览器了。
这也给开发者上了宝贵一课:一旦失去信任,我们中有太多人会纯粹基于原则永不重蹈覆辙。
其他问题也层出不穷:
https://news.ycombinator.com/item?id=18734999
https://www.sophos.com/en-us/blog/brave-ceo-apologises-for-a…
https://www.bleepingcomputer.com/news/security/facebook-twit…
以及Tor相关问题(现已修复)
https://www.coindesk.com/tech/2021/02/22/brave-browser-was-e…
为什么Mozilla不为其浏览器开发或采用这样的引擎?打造真正原生的广告和干扰处理方案。讽刺的是,Brave浏览器却明智地采用了被Mozilla弃用的Rust语言。我知道Mozilla似乎有广告处理功能,但老实说除了那个盾牌图标,我根本不清楚它到底能做什么。
Mozilla希望Firefox成为人人皆可使用的主流浏览器。广告拦截会引发网站故障风险,而绝大多数用户缺乏处理这类问题的技术知识。
以下是Firefox默认拦截的内容:https://support.mozilla.org/en-US/kb/enhanced-tracking-prote…
Mozilla几乎所有资金都来自谷歌——一家广告公司。他们怎会自断生路?
因为Mozilla主要由谷歌赞助。
因为Firefox默认不提供广告拦截功能。它不像Brave那样立场鲜明,这既有优点也有缺点。
维护Firefox越来越困难了。Brave的分屏标签功能看似简单却如此精妙。
禅浏览器——作为火狐的衍生版本,同样支持分屏标签页(以及空间模式、垂直标签页、快速浏览等众多功能)。该项目近几年保持着相当活跃的更新节奏。
Firefox自146.0版(2025年12月9日)起在about:config中隐藏了实验性分屏标签功能
https://winaero.com/how-to-enable-split-view-in-firefox-146/
十年前有个名为Tile Tabs的Firefox插件,能实现任意数量的标签页拆分。它已随所有旧式XUL插件一同消亡。
1. 寻找除Firefox外同样值得信赖的新浏览器。
2. 考虑Brave浏览器——参见第1点。
如今省下45MiB内存,实在不知该有多惊讶。
45MiB是默认广告拦截配置的节省量,启用更多拦截列表时节省空间会相应增加。
我乐见性能提升,毕竟如今多数产品都忽视效率优化。
每次请求都会访问广告拦截数据;所以这45MiB是CPU缓存的节省量。
除非是遍历整个列表的线性搜索,否则我怀疑能节省这么多缓存空间。
这种看法有误。提升复杂软件的性能并非一蹴而就,甚至不是十几个小步骤就能完成的。这是需要数年时间积累众多个位数百分比改进,同时谨慎避免性能退化的工作。
确实如此,毕竟不久前你还说过“如今省下4.5MB内存实在没什么值得惊叹的”。还记得当年emacs被戏称为“八兆内存不断交换”吗?那同样是不久前的事。如今八兆内存不过是某个微不足道的JS库占用的空间——它作为某个可怜的npm包的一部分,只为在你的浏览器窗口里硬塞广告。
尽管尽情惊叹吧,但我认为开发者对此的重视是个好兆头。既然这是免费产品,无论性能提升幅度多大,我们都该为此欣喜。
> 如今
你是指当前内存价格,还是众多Electron应用的臃肿问题?
130美元的摩托罗拉手机都有8GB内存。这最多节省0.5%内存,在现代系统里根本微不足道。
但乘以所有应用/服务/扩展/配置文件后,累积量就可观了。
正是这种偷懒思维导致当今软件如此臃肿迟缓。
累积效应确实存在,但需要重写所有软件,成本相当高昂。
我认同这种观点,但现在为时已晚。
问题根源在于软件设计追求开发成本的廉价化。
如今的优化成本远低于过去。
这个结论基于什么?能详细说明吗?
纯粹基于使用LLM的个人经验。过去一年我优化了许多原本没时间处理的事项,尤其是构建系统/管道。
这只是Brave浏览器,别把每种服务都乘以倍数
你对待单个软件的态度,最终会蔓延到所有软件。
“节省X%内存”根本不成立,因为内存本身就是压缩交换空间和/或映射文件的缓存。
核心教训在于:指针追踪的数据结构和树形结构,其开销远比所有人(包括大多数编程语言)所宣称的要高得多。
如今在这个价位段,你只能拿到4GB内存,而系统还要占用部分内存,导致用户可用空间更加紧张。
问题不止于此,因为当内存使用量过大时,性能通常也会大幅下降。这是因为CPU受限于缓存瓶颈。因此内存越大,缓存刷新频率就越高,缺失次数随之增加,这会严重影响性能。
智能手机厂商已宣布今年将削减内存配置…仅供参考
现在请为同时打开200个标签页的用户计算性能损失。要知道当前浏览器基本都采用“每个标签页独立进程”的机制。
现代浏览器不会将200个标签页都保存在活动内存中。这种情况十多年来就已不复存在。
但每个窗口的活动标签页确实会驻留内存。Firefox甚至会持续渲染所有窗口中的活动标签页——即便这些窗口处于不可见状态。
不确定这45MB是按浏览器实例还是按标签页计算,但若是后者,关闭10个窗口可节省450MB内存。在低端设备上这超过10%的节省相当可观。
其中4GB被系统占用。运行时环境占用更多内存也意味着需要更多CPU资源来追踪和释放内存。
正是这种态度导致如今一切都如此臃肿…
两周后裸DIMM条8GB内存130美元将是合理价格。
我今天就能以不到两倍的价格卖你16GB内存条,让你赚一笔。
确实如此。
但为什么不用Firefox加uBlock呢?Brave本质也是Chrome。如果谷歌断供,Brave或其他浏览器还能算什么?
有趣的是iOS更新说明完全没提及:
> 本次更新:
> 其他增强功能、稳定性改进及安全更新
对效率提升或广告拦截只字未提!
iOS版Brave是否实际使用相同代码库?据我所知,iOS所有浏览器都需封装Safari内核,这或许能解释更新说明的缺失。不过我并非iOS开发者,此处理解可能有误。
我们所有平台(包括iOS)均采用相同的广告拦截引擎(adblock-rust),因此能实现内存共享优化。
原文写道:
Brave现在真的算好浏览器了吗?他们重写代码了吗?上次用时还觉得它是个JavaScript垃圾堆。
这是我用过最有效的广告拦截器。因此在我看来它比Chrome更出色。试试看吧,它也是我日常网页开发的工具(仅需Chrome调试器)
> 一团糟的JavaScript烂摊子。
你可能想的是Vivaldi。Brave确实存在bug,但它并非用JavaScript编写的。
该项目在GitHub上标注为100% JavaScript https://github.com/brave/brave-browser
https://github.com/brave/brave-browser
>此仓库存放用于构建macOS、Windows和Linux版Brave桌面浏览器的构建工具。
浏览器本体在此:https://github.com/brave/brave-core (占TypeScript代码量的8%)
它比Chrome更出色:无广告、运行更快(正因无广告)、还具备诸多实用功能。有何不爱?
它包含大量可疑的遥测数据
不过Brave在Linux系统仍占用300MB/标签页,Windows系统甚至接近700MB/标签页。可见他们还有很长的路要走。
这完全是谎言。当仅打开news.ycombinator.com一个标签页时,整个浏览器仅占用约400MB内存。单个标签页本身约占35MB,新增标签页按相同比例递增。
https://imgur.com/a/nNA90lk
他们在广告拦截方面做得超棒。我就是冲着这个功能喜欢的。
没错,但有些人希望使用的软件背后是值得信赖的国家里值得信赖的公司。少占45MB内存不足以抹去Brave的历史污点。他们偷偷安装VPN和添加自有联盟链接的行为至今令人难忘。
好奇切换到FlatBuffers对性能提升的具体贡献。
FlatBuffers绝对是主要优化点!
在64位系统中,指针本身会消耗大量内存(尤其当广告拦截规则超过十万条时)。改用数组索引替代指针,避免了对整个潜在内存空间的寻址需求,从而节省了大量原本浪费的内存。
见解深刻,非常感谢。
众所周知FlatBuffers会导致客户端代码膨胀,是否采取了任何缓解措施?
我猜代码膨胀程度与模式复杂度成正比,而性能提升则与数据量成正比,因此在拥有大量庞大屏蔽列表的广告拦截器中,后者占据主导地位。
我们最大的改进在于通过生成器引用已输出对象实现去重。别对JSON运行flatc,它做不到这点。
为何不把这些广告置于布隆过滤器之后?即便使用FlatBuffers,这仍会消耗大量内存。
有趣的是我们早在2019年就用过布隆过滤器:https://brave.com/blog/improved-ad-blocker-performance/
Brave浏览器是我能忍受iPhone的唯一理由 )
Brave还在未经许可的情况下,在我Windows设备上安装了VPN及VPN服务,卸载后甚至未禁用或删除Windows任务计划程序中的3项独立计划任务。该VPN问题在GitHub上悬而未决长达8个月以上——起初他们还矢口否认此事。据我所知它可能仍在安装,但当时我已清除这类恶意软件,所以无法确认。
此事之后我再也不会信任他们。
你在这篇HN帖子下评论了三次(?)并在本站多次提及此事。看来你确实有怨气要发泄。
他们安装的VPN处于禁用状态,必须用户手动激活才能启用。这么做的唯一目的,就是让你在浏览器点击“激活VPN”时能立即生效。
更甚者,其他公司也曾(或仍在)使用类似伎俩。多年来,macOS版Dropbox就通过特定漏洞获取额外权限来加速同步。更别提Firefox曾通过偷偷安装的隐形扩展程序在用户浏览《黑客军团》相关页面时注入广告。
Brave的操作依然愚蠢至极,就像在加密货币链接中添加自家联盟链接(若原链接未含联盟链接)——这种操作既能为公司创造额外收益,又不会增加用户成本。不过这事更早以前就发生了。
无论如何,他们确实资助或开发了大量反广告技术与研究,并将其开源/公开发布。Brave的默认设置比Firefox更能保护用户隐私。迄今为止,其BAT概念仍是广告资助互联网模式下唯一合法的替代方案。
Brave正是Mozilla梦寐以求的模样。
浏览器安装程序借便利之名,在未经我同意的情况下偷偷安装无关网络服务,事后还搬出毫无关联的转移话题论调。你的评论剩下的部分我懒得看了。
没错,我必须提醒大家警惕Brave华而不实的公关话术。如此行事的公司终将付出代价。
Brave现在真的屏蔽广告了吗?还是依然用“扫描我的加密货币”广告替代?
与其他回复者不同,我并非Brave员工,但可以确认Brave从未实施过这种操作。他们确实有自有广告,但始终采用主动选择加入机制(默认不参与),且会向选择加入者支付少量美元等值的加密货币代币——不过是几美分而已。人们或许嗤之以鼻,但请想想:那些强制展示广告却分文不付的公司——简直是所有其他浏览器。
你可能想的是:曾有段时间访问某些网址时,浏览器会自动重写网址添加联盟链接。此举引发强烈反弹,据我所知他们已迅速移除该功能且再未启用。
关键细节遗漏:他们从未告知用户URL重写机制,仅在被曝光后才撤销操作。
> 浏览器会自动替换URL植入联盟链接
公平地说,这种操作极其阴暗,即便多年后仍值得被质疑。
> 还是会用“扫描我的加密货币”广告替换?
Brave从未这么做过。
Brave默认拦截第三方广告和追踪器。
(免责声明:我负责Brave的隐私保护与广告拦截业务)
负责什么?https://archive.is/W0k4j
(免责声明:人们记得Brave有多可疑)
那只是个概念,据我所知从未进入正式版本。
他们本该效仿正规浏览器,直接从谷歌拿走数亿美元。
别忘了他们曾代收其他网站捐款,除非运营方主动去“托管账户”提取,否则资金就归他们所有
拨款来自我们的代币基金,而非用户代币(当时根本无法购买BAT)。
我后来发现并立即修正的问题是侵犯了公开权,与用户自有代币的捐赠无关。
耶稣啊,你难道没看出来他们至少在尝试替代其他广告公司未经同意的肛门探测?
已经分享过了,但你链接的那篇只是提案,从未公开发布过任何可交付成果。当时仅由少数员工测试过简易原型——广告位会显示蓄须男子的图片作为占位符。若方案可行,这张搞笑图片将替换为真实代码。但最终方案流产,该创意及代码在我加入Brave前就被搁置了(我2016年8月入职,至今近十年)。
免责声明(以防不明确):本人系Brave员工
我几年前确实试用过Brave,确实收到大量加密货币广告。真不明白你凭什么靠撒谎获得赞同。
或许你当时忘了吃药。
这种指控太离谱了,相关证据至今仍可在线查证:https://brave.com/blog/binance/
攻击个人而非观点的做法完全违背了HN的精神。
那篇博文讨论的是合作关系(现已终止),但你当时可能在新标签页看到过赞助图片(记得当时是4张中的1张,其余均为艺术图)。
这些是经过严格设计的非追踪品牌广告图(包含Brave审核流程),并非插入发布商页面的广告(我们从未这样做过),也非(仅限用户主动选择的)推送通知。
Brave一直在探索可持续运营模式,这些赞助图片仍是重要收入来源,尽管目前占比已低于其他渠道。若您不愿看到,可随时关闭该功能。
免费使用始终是用户权利,我们原则上不加以阻止——毕竟开源项目本就无法完全控制。但天下没有免费的午餐:使用Firefox意味着成为谷歌的产品;使用Firefox分支则意味着免费使用维护成本高昂的Gecko引擎。希望对你有帮助。
“赞助图片”
你究竟认为广告是什么?
令人难以置信的是,人们竟能凭空编造出如此荒谬的幻觉——仅仅因为对布伦丹·艾奇的仇恨已让他们神智失常。
或许GP记得的是他们偷偷安装的VPN,悄然添加的联盟链接,为其他公司收取却据为己有的捐款,或是Brave被曝光的其他丑闻。当我们清楚目睹他们如何处理可见的事物时,竟还有人认为代码库值得信赖,这实在令人费解。当然,尽管继续把责任推给那个鲜为人知的家伙吧。
鉴于上述谎言被反复传播又被纠正的次数——近几年几乎每个Brave讨论帖都出现过——我倾向于认为,持续散布这种谣言的动机实属恶意。
此事从未发生。